
在輝煌的K8、平淡的K10架構之後,AMD的“推土機”(Bulldozer)模塊化多核CMT架構承載了他們的新希望,但2011年發布以來,AMD的CMT架構折戟沉沙,期間AMD雖然升級了打樁機(Piledriver)、壓路機(Steamroller)及挖掘機(Excavator)等四代模塊架構,但FX系列處理器已經一蹶不振。如今重壓之下的AMD依然把高性能服務器市場作為重點,他們的籌碼這次壓在了全新的X86架構Zen上,從日前曝光的Zen架構核心圖上我們可以確認AMD這次真的是徹底放棄模塊多核設計了,回歸傳統。
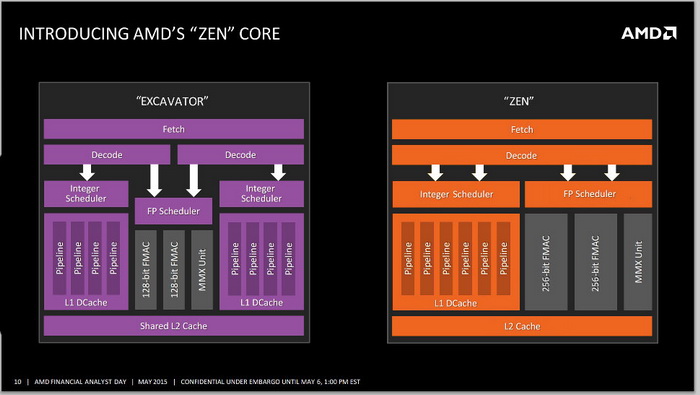
AMD的Zen架構搞了很多年了,目前對該架構所知甚少,此前只知道AMD會放棄“推土機”那樣的CMT模塊多核,回歸傳統的SMT同步多線程,TDP還會更低。日前有網友在Planet3dnow論壇上曝光了AMD官方的PPT,這是AMD 5月份的會議上才會公佈的資料,上面赫然列出了Zen架構的內核設計,並與目前的Excavator挖掘機架構做了對比。
AMD的模塊多核設計架構最明顯的就是2個整數單元搭配1個彈性浮點單元,整數單元各自有自己的解碼器和調度器,而浮點單元是共享設計的。AMD採用這種設計是因為日常應用中有80%的運算都是整數型的,浮點運算只有20%,而且AMD當時還在搞APU融合計算,他們希望浮點運算轉向能力更強的GPU方面。
理想很豐滿,現實很骨感,可惜AMD的這種設想在現實中並沒有發揮出優勢,“推土機”的實際性能並不強。此外,AMD當時使用的還是32nm SOI製程,Globalfoundries缺乏先進製程的頑疾也加劇了“推土機”的失利,功耗大、發熱高,再加上性能不濟,AMD的FX處理器自此就沉寂下來了。
AMD的模塊化架構上使用的是彈性浮點單元設計
如今AMD攜Zen歸來,它不再使用模塊化設計了,回歸了傳統的整數單元+浮點單元的設計,當然每個單元的功能現在已經今非昔比了,比如“挖掘機”架構中浮點單元是128bit的,Zen架構中則是256bit的,將支持Intel的AVX 2.0指令。
不僅如此,AMD的FP單元具備很高的彈性,之前推土機架構中2個128bit浮點單元可以合併執行256bit指令,Zen架構的2個256bit單元理論上可以執行512bit指令,達到Intel Skylake處理器的水平。
另外,在快取的部分也有了重大的變化,Zen架構中每個核心搭配512KB L2,而4個核心將組成一個單元,共享8MB L3快取,與Intel的處理器設計類似。
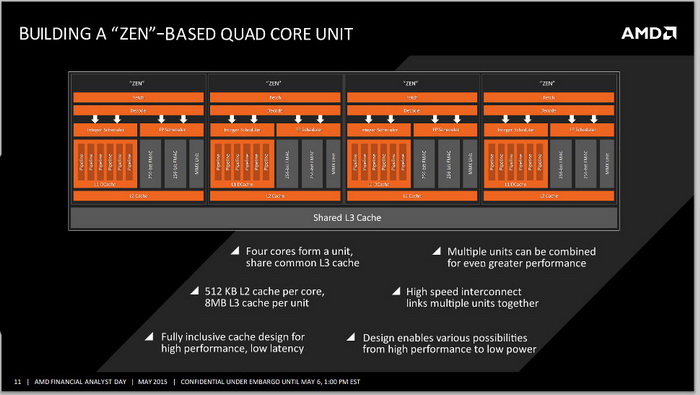
從圖上看,AMD把四核Zen架構核心稱為一個單元,每個核心有自己的512KB L2,4個核心共享8MB L3。單從容量上來看,8MB L3的配置跟目前的模塊化設計是相同的,512KB L2則只有“推土機”模塊的一半容量,但實際上內部大有玄機。
AMD自從K6架構開始使用專有快取(exclusive cache)設計,快取之間的數據不通用,這種設計主要是為了提高快取利用效率,在“推土機”架構之前這都沒什麼問題。但是,之前我們對推土機架構失利做過分析,影響模塊多核性能的一個因素就是AMD的快取設計,快取間關聯性太低,分支預測效率不高,命中率不高。
所以Zen架構中AMD的快取容量看起來小了,但改為包含式快取(inclusive cache),也就是說L1中的數據可以跟L2中的數據共享,這跟Intel的處理器快取設計是一樣的。
從圖片上來看,AMD一直在強調Zen架構的多核單元可以更高效地並聯,4個核心為一組單元,之前曝光過的16核Zen架構APU、32核Zen架構都可以此為基礎組合而成。
Zen架構預計今年底問世,但產品上市可能要等到明年了,此前已經曝光的Zen架構16核APU、Zen架構32核伺服器晶片看上去也各種強大,希望Zen架構不要再跟推土機這麼杯具了。
實際上對Zen可以保持謹慎樂觀,首先參與Zen架構研發的設計師Jim Keller是個技術大牛,早前負責過AMD的K7及64位K8處理器的研發,之後投奔蘋果,參與了蘋果A4/A5處理器的開發。再次,推土機失利很大一個原因也是GF製程不行,當時還在使用32nm SOI,但Zen架構將會使用GF的14nm FinFET,後者使用了三星的14nm授權,成熟度比GF自己搞的好多了。2016年Intel的主流製程也是14nm 3D晶體管,雖然各自的設計不同,但AMD終於能跟Intel使用同代水平的半導體製程了。
來源:
http://www.expreview.com/40213.html
http://www.expreview.com/40239.html
AMD的Zen架構搞了很多年了,目前對該架構所知甚少,此前只知道AMD會放棄“推土機”那樣的CMT模塊多核,回歸傳統的SMT同步多線程,TDP還會更低。日前有網友在Planet3dnow論壇上曝光了AMD官方的PPT,這是AMD 5月份的會議上才會公佈的資料,上面赫然列出了Zen架構的內核設計,並與目前的Excavator挖掘機架構做了對比。
AMD的模塊多核設計架構最明顯的就是2個整數單元搭配1個彈性浮點單元,整數單元各自有自己的解碼器和調度器,而浮點單元是共享設計的。AMD採用這種設計是因為日常應用中有80%的運算都是整數型的,浮點運算只有20%,而且AMD當時還在搞APU融合計算,他們希望浮點運算轉向能力更強的GPU方面。
理想很豐滿,現實很骨感,可惜AMD的這種設想在現實中並沒有發揮出優勢,“推土機”的實際性能並不強。此外,AMD當時使用的還是32nm SOI製程,Globalfoundries缺乏先進製程的頑疾也加劇了“推土機”的失利,功耗大、發熱高,再加上性能不濟,AMD的FX處理器自此就沉寂下來了。
AMD的模塊化架構上使用的是彈性浮點單元設計
如今AMD攜Zen歸來,它不再使用模塊化設計了,回歸了傳統的整數單元+浮點單元的設計,當然每個單元的功能現在已經今非昔比了,比如“挖掘機”架構中浮點單元是128bit的,Zen架構中則是256bit的,將支持Intel的AVX 2.0指令。
不僅如此,AMD的FP單元具備很高的彈性,之前推土機架構中2個128bit浮點單元可以合併執行256bit指令,Zen架構的2個256bit單元理論上可以執行512bit指令,達到Intel Skylake處理器的水平。
另外,在快取的部分也有了重大的變化,Zen架構中每個核心搭配512KB L2,而4個核心將組成一個單元,共享8MB L3快取,與Intel的處理器設計類似。
從圖上看,AMD把四核Zen架構核心稱為一個單元,每個核心有自己的512KB L2,4個核心共享8MB L3。單從容量上來看,8MB L3的配置跟目前的模塊化設計是相同的,512KB L2則只有“推土機”模塊的一半容量,但實際上內部大有玄機。
AMD自從K6架構開始使用專有快取(exclusive cache)設計,快取之間的數據不通用,這種設計主要是為了提高快取利用效率,在“推土機”架構之前這都沒什麼問題。但是,之前我們對推土機架構失利做過分析,影響模塊多核性能的一個因素就是AMD的快取設計,快取間關聯性太低,分支預測效率不高,命中率不高。
所以Zen架構中AMD的快取容量看起來小了,但改為包含式快取(inclusive cache),也就是說L1中的數據可以跟L2中的數據共享,這跟Intel的處理器快取設計是一樣的。
從圖片上來看,AMD一直在強調Zen架構的多核單元可以更高效地並聯,4個核心為一組單元,之前曝光過的16核Zen架構APU、32核Zen架構都可以此為基礎組合而成。
Zen架構預計今年底問世,但產品上市可能要等到明年了,此前已經曝光的Zen架構16核APU、Zen架構32核伺服器晶片看上去也各種強大,希望Zen架構不要再跟推土機這麼杯具了。
實際上對Zen可以保持謹慎樂觀,首先參與Zen架構研發的設計師Jim Keller是個技術大牛,早前負責過AMD的K7及64位K8處理器的研發,之後投奔蘋果,參與了蘋果A4/A5處理器的開發。再次,推土機失利很大一個原因也是GF製程不行,當時還在使用32nm SOI,但Zen架構將會使用GF的14nm FinFET,後者使用了三星的14nm授權,成熟度比GF自己搞的好多了。2016年Intel的主流製程也是14nm 3D晶體管,雖然各自的設計不同,但AMD終於能跟Intel使用同代水平的半導體製程了。
來源:
http://www.expreview.com/40213.html
http://www.expreview.com/40239.html
