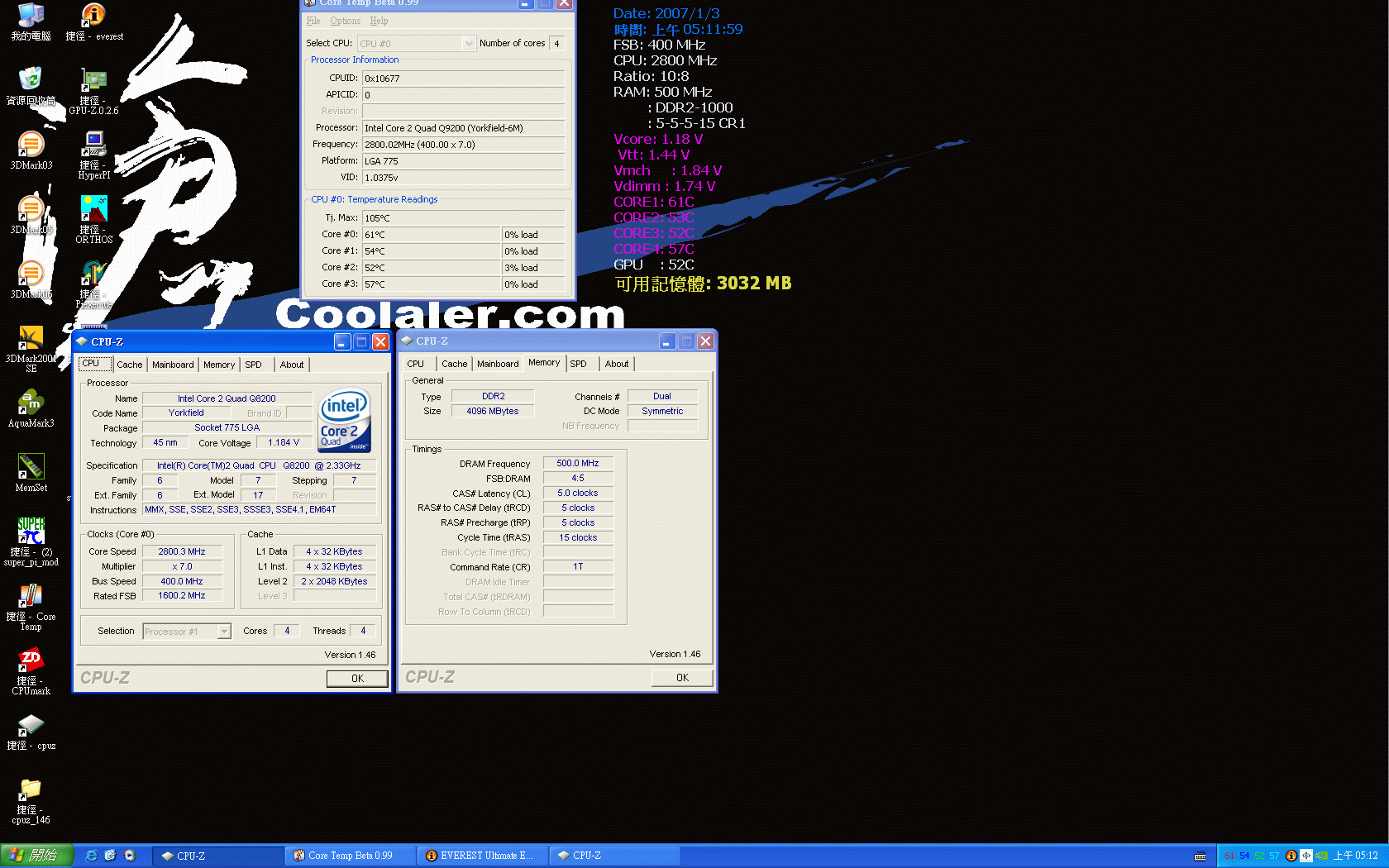
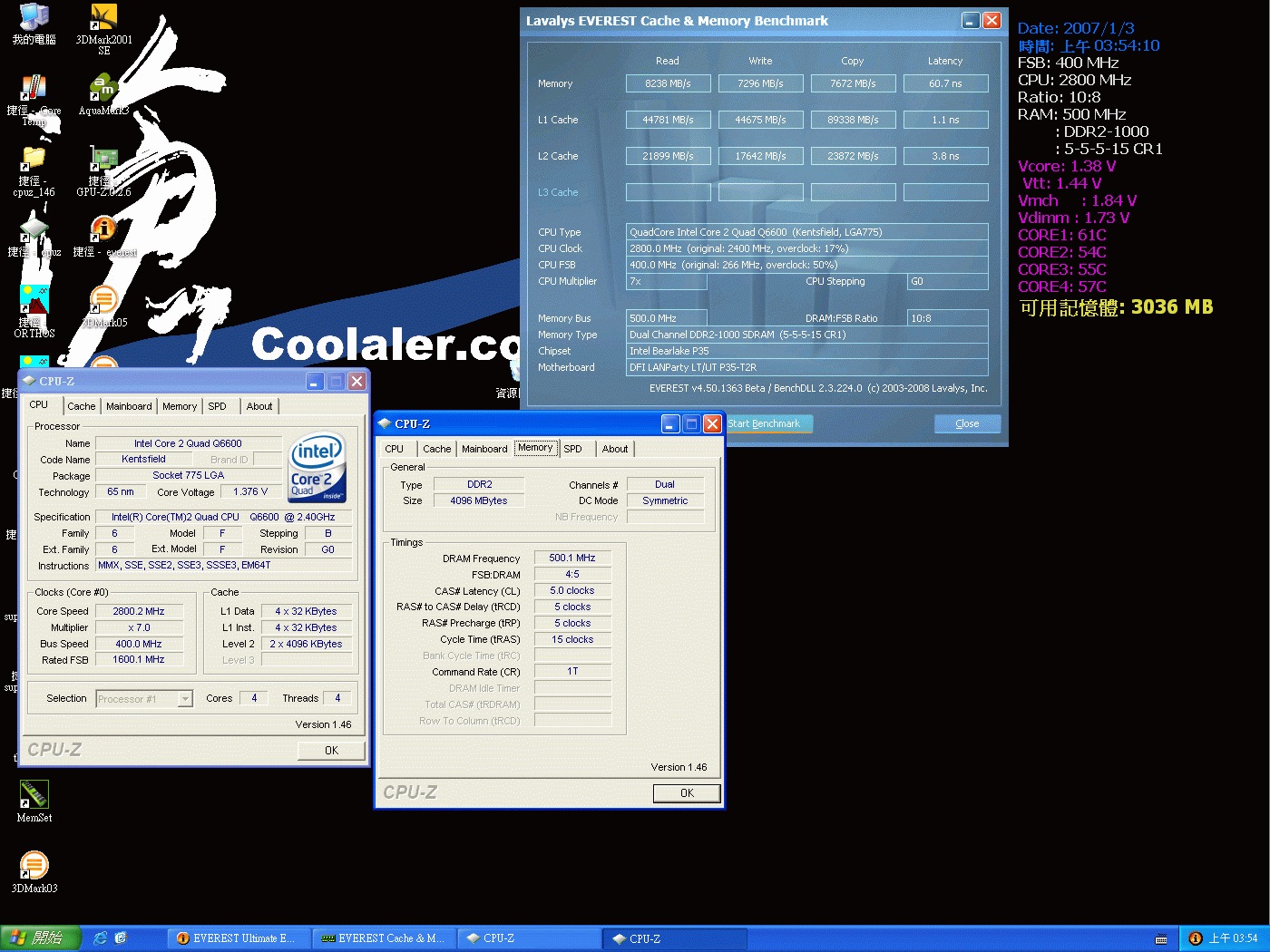
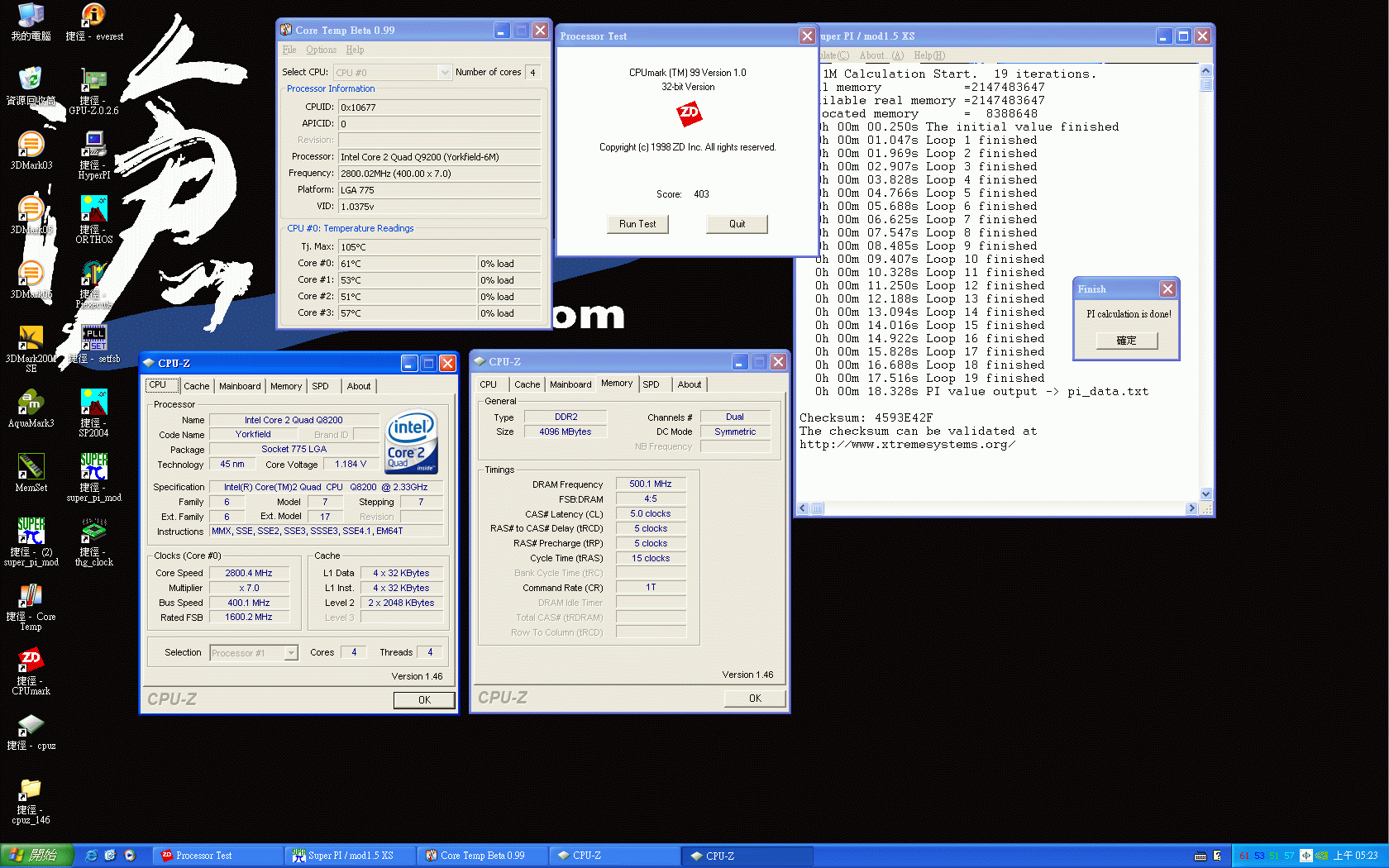
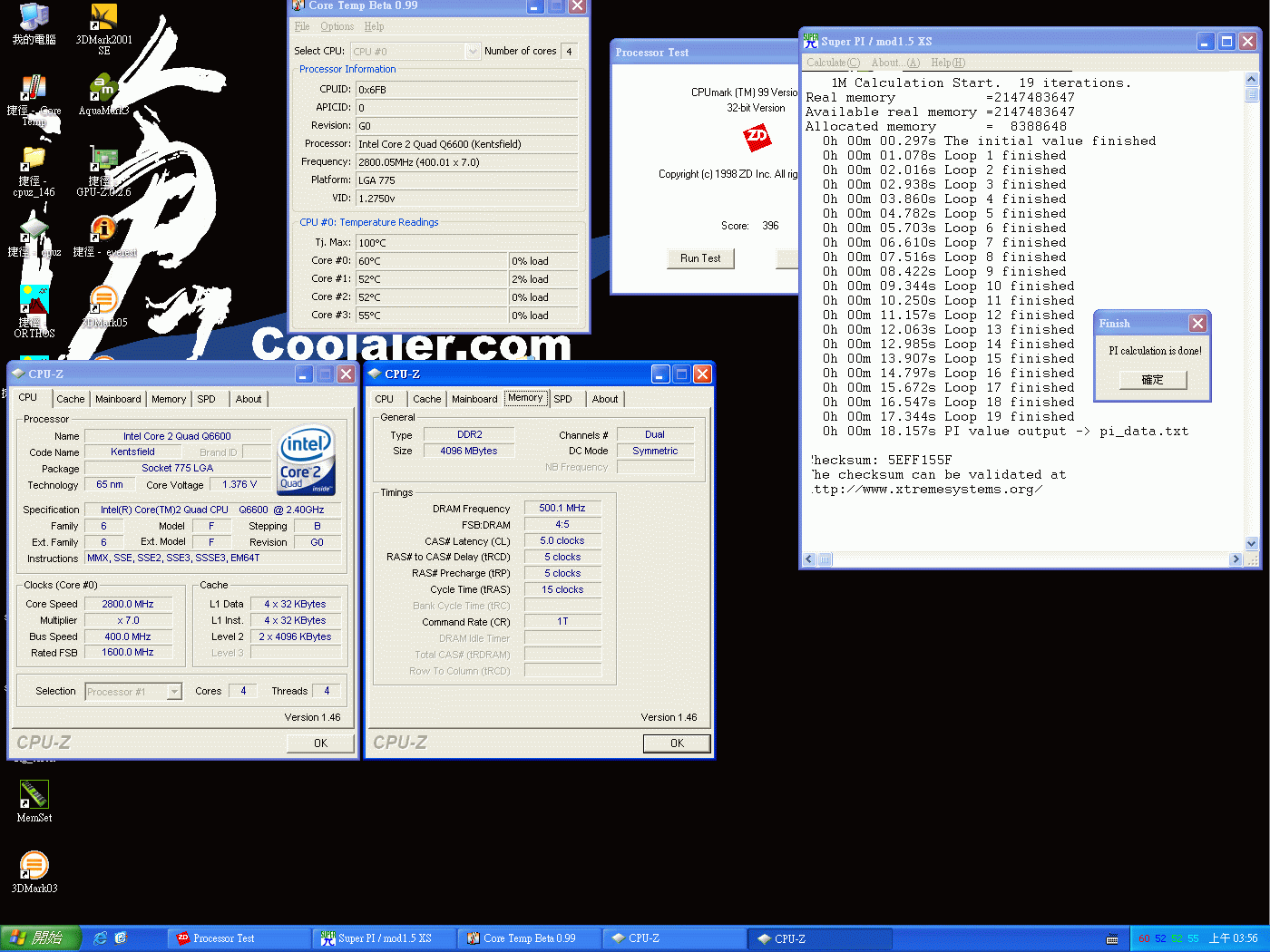
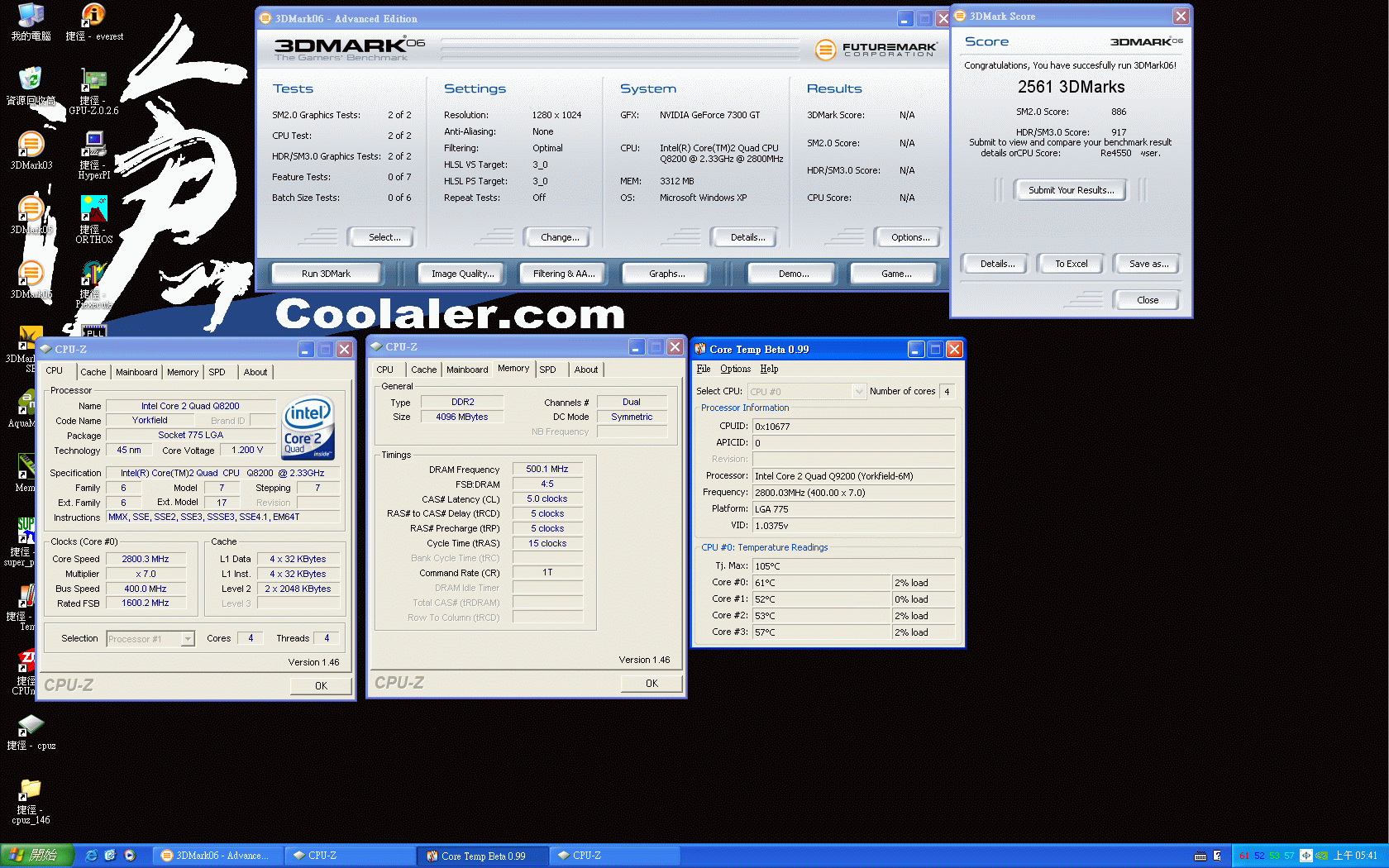
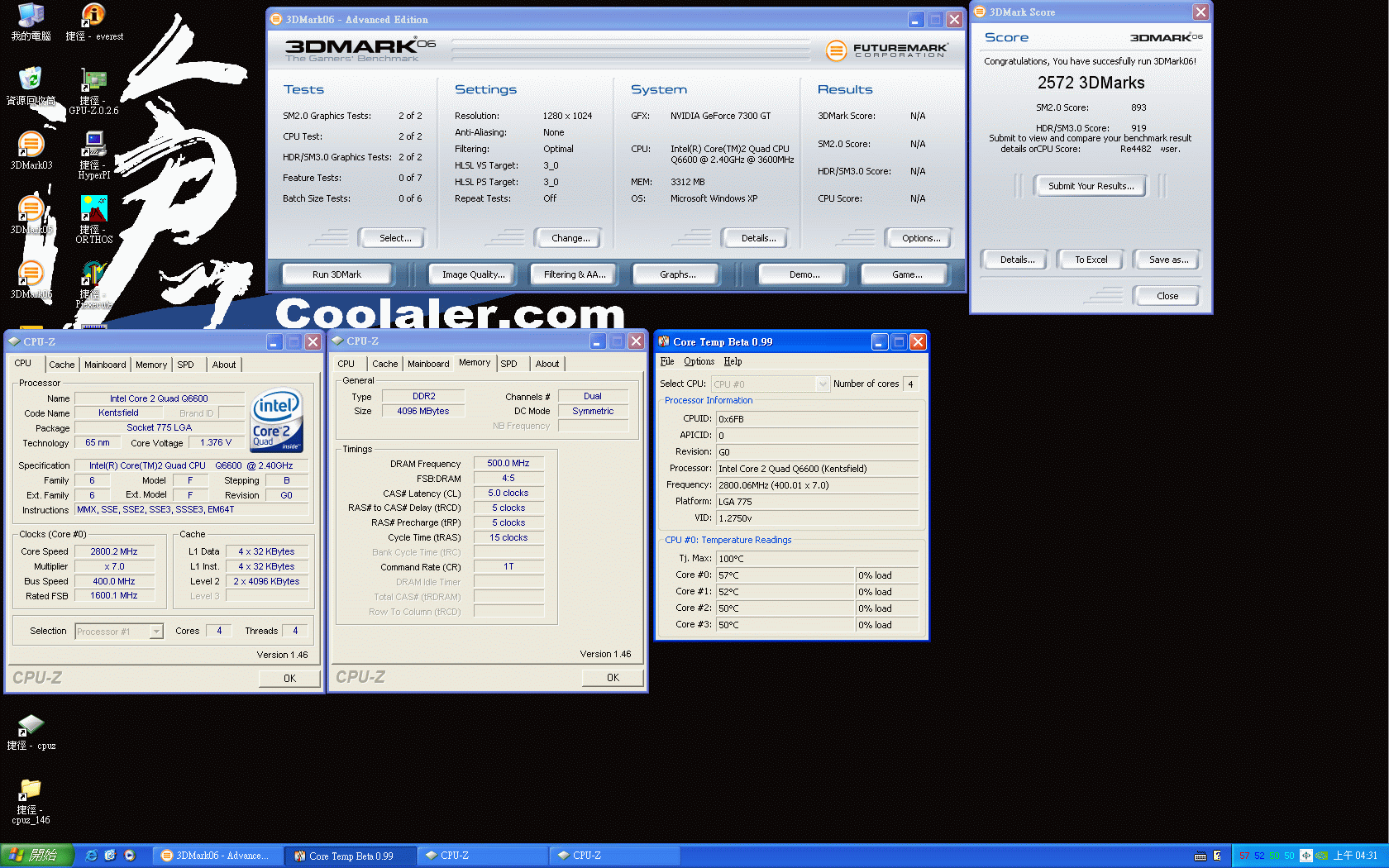
和Q6600相比,Q8200除了具有低溫省電的優勢外,最令人矚目的是Q8200擁有了SSE 4.1指令集的支援
那麼甚麼是SSE 4.1指令集呢?
來看看SSE 4.1指令集的理論介紹
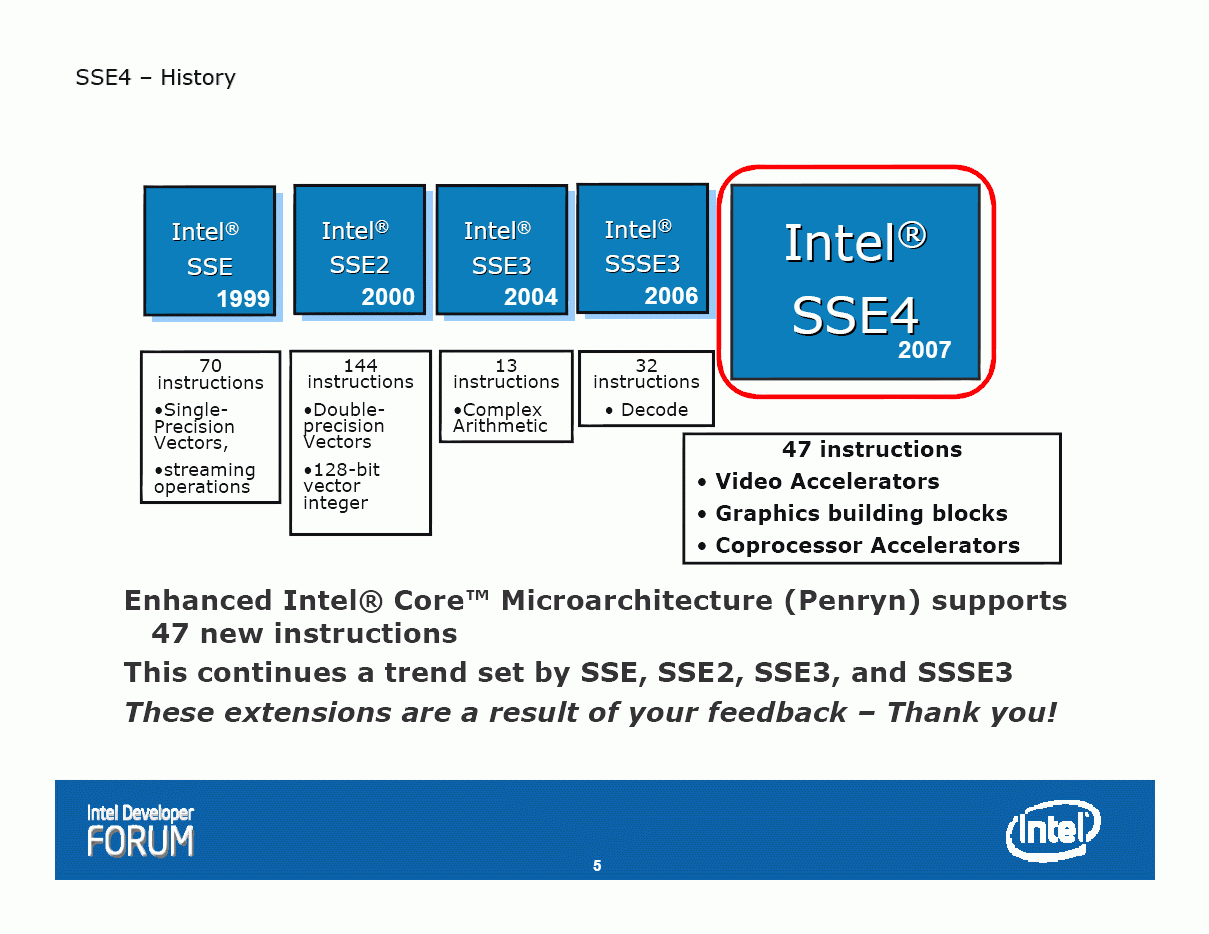
英特爾的SSE4(流式單指令多資料擴張)指令集包含了54條新指令,其中的47條指令在Wolfdale/Penryn上實現,被稱作SSE 4.1,而剩下的7條SSE4指令將在代號Nehalem架構的45納米處理器上開始實現
根據架構代號,這類指令擴展在正式命名之前通常一個別名,例如SSE是KNI、SSE2是WNI、SSE3是PNI、SSSE3是TNI,SSE4目前看來沒有這樣的名頭,也許被稱作SNI(Swing New Instructions,根據英特爾的10.0版編譯器開關來看)
基本這些*NI的頭一個字母就是取自引入該指令擴展的微架構第一個字母
在Q6600時代引入的SSSE3最初是準備在Tejas(Prescott架構的下一代)上引入的,在一段時間裡曾經被誤認為是SSE4,而SSE 4.1的引入主要是為了提升x86處理器在視頻編緝、圖形處理等效能
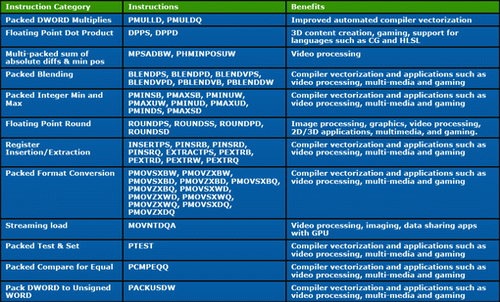
SSE4.1——單指令32位元組差分絕對值求和(SAD)運算
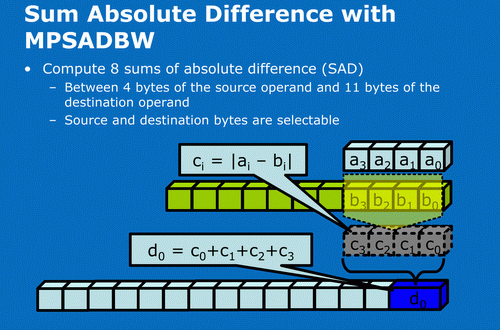
其中的MPSADBW(有時候為了簡化稱呼人們又將它稱之為MPSAD)能實現單指令完成32位元組的差分絕對值求和(SAD)運算:
在上圖中,a0~a3(共計32個位元組)首先會分別減去b0~b3,然後對這四個減法算後的差的絕對值(c0~c3)作求和運算得到一個目的數存放在d0
MPSADBW的源數和目的數位元址以及都是可選的
和SSE3的PSAD相比,SSE4.1的MPSADBW單指令資料處理能力為PSAD的兩倍
上圖為SSE4和SSSE3在處理獲取兩個8x8塊的SAD例子,SSE4只需要9條Intrinsic指令(類似彙編,可以看作是彙編指令在高階語言中的表現形式,但是更加靈活)就能達成,而SSSE3則需要31條Intrinsic指令
從上面的這段程式的程式路徑長度上來看SSE 4.1的確是帶來了不少的優勢
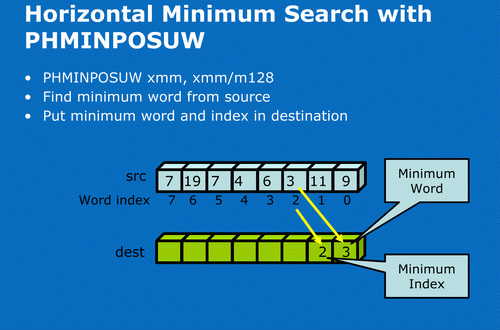
SSE4.1——水準最小值查找
PHMINPOSUW是另一條SSE4.1中和視頻處理中的運動評估密切相關的擴展指令
SSE4.1——整數格式擴展轉換
PHMINPOSUW的作用是對獲取同一行位址中的資料(UWORD)最小值後將其存放在目的地址中並給予其位置的編號,在整數操作和子圖元運動評估中這樣的操作是經常使用的
在視頻加速方面SSE4.1還有12條整數格式轉換指令,能單指令完成單字節(Byte)、字(WORD)、雙字(DWORD)轉換至字(WORD)、雙字(DWORD)、四字(QWORD)格式
它們就是PMOVSXxx、PMOVZXxx,其中的xx對應6種整數格式,例如xx為BW就是8個packed起來的8位元整數,這12條整數格式轉換指令還可以用於圖片、音訊處理的加速
英特爾表示,和Conroe架構Core 2 2.93GHz 1066MHz FSB採用SSE2相比,45nm的Core 2 3.33GHz 1066MHz FSB採用SSE4+SSSE3可以在微軟SSE4+SSSE3優化版視訊轉碼器中提供多達40%的程式級性能提升
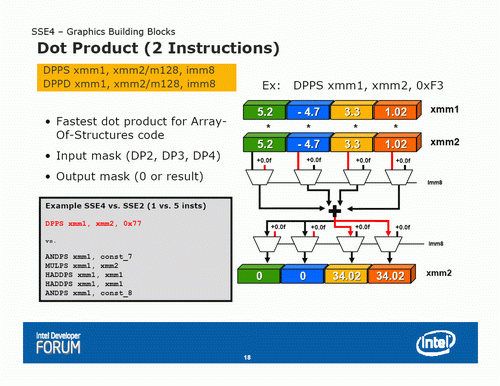
SSE4.1——點積、雙字乘、條件位置混合、取捨等
在圖形處理加速方面,SSE4.1包含了Dot Product、DWORD MUL、往XMM寄存器插入或者從XMM寄存器提取資料、條件位置混合、取捨等
其中最為吸引的就是DPPS(單精確度,單指令4D向量)和DPPD(雙精度,單指令2D向量),在3D運算中,Dot Product指令的使用密度相當高
一條4D向量的Dot Product指令在D3D shader中稱作DP4)相當於包含了4個乘法和3個加法運算操作
和使用SSE2指令編寫的程式,SSE4.1跑一次4D單精確度dot product只需要一條DPPS就能達成,而SSE2需要5條指令才能達成
D3D中的DP4指令描述
dest.x = dest.y = dest.z = dest.w =
(src0.x * src1.x) + (src0.y * src1.y) +
(src0.z * src1.z) + (src0.w * src1.w)
條件位置混合其實就類似於D3D9 Pixel Shader 2.x引入的swizzle操作方式,能夠對向量寄存器中的某個component作操作
英特爾SSE4仍然缺乏MAD(或者說MAC)指令的支援,這可能是因為x86原則上極少有3個運算元(operands)的指令,不過在AMD的SSE5中,我們看到了首次大量引入3 operands
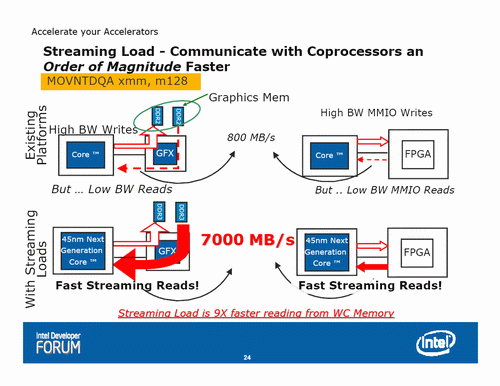
SSE4.1——單指令64位元組Streamimg Load能力
SSE4不僅僅對邏輯運算實現了指令擴展,還引入了被稱作Steaming Load的Load指令擴展,不過在介紹它之前我們有必要簡單瞭解一下UnCacheable或者說non-cacheable(不作緩存)的概念
non-cacheable記憶體通常是因為CPU要和其他設備共用的時候而設定的,這是為了避免資料被cache起來而沒有實際寫進和其他設備(例如顯示卡)共用的記憶體中
在記憶體中某個區域被設定為non-cacheable後,任何需要寫進該區域的資料都會忽略掉L1/L2 cache的存在而必須被立刻寫進到這個non-cacheable記憶體對應的位置中
但是如果每次寫入的資料只有32bit大小,存儲的效率將會非常糟糕,因為記憶體控制器的通道在Pentium的時候已經是64位寬了
為此人們也引入了被稱作Write-Combining(合併寫)的方式,在CPU上建立一小塊cache,這塊小cache是和一致性cache(例如L1 cache/L2 cache等)完全獨立的快取記憶體
這個緩存被稱作Write-Combining Buffer,大小基本上就是一個或者若干個cache-line的大小(在Wolfdale/Penryn上的cache-line是64-byte)
需要寫入到non-cacheable記憶體的資料會被先存入到Write-Combining Buffer,待這些資料達到一定大小的時候(例如64-byte),就執行存入到non-cacheable記憶體中的動作
由於記憶體一次存取的資料越多,效率就越高,因此採用Write-Combining後,可以顯著提升不需要頻繁修改操作的non-cacheable記憶體操作效率
在SSE2的時候,英特爾還引入了MOVNTDQ/MOVNTPD,作用也都是每次向non-cacheable緩存存入64個位元組長度的資料再以Write-Combining的方式向指定的記憶體位址存入這128-bit資料
這兩個指令不同的地方在於MOVNTDQ的源運算元是Packed起來的整數(可以是位元組、字、雙字、四字),而MOVNTPD是Packed起來的兩個雙精度浮點數
雖然non-cacheable記憶體的主要操作是把資料寫到主記憶體中,但是有時候也許要從non-cacheable記憶體載入(Load)資料的
例如GPU把渲染完的資料存放到non-cacheable記憶體,由CPU作進一步的加工處理,這時候CPU就需要執行直接從non-cacheable記憶體載入(Load)資料的操作了
SSE2的MOVDQA一次可以從主記憶體中load 128bit資料到Write-Combining Buffer中,只能填滿1/4的cache-line,如果CPU執行的程式要處理的資料是連續的話,這16byte後的資料就又得再從主記憶體中讀取一次或者說MOVDQA指令需要再執行一次
而SSE4.1的MOVNTDAQ能以每次從non-cacheable記憶體中連續地載入64位元組長度的資料(只要符合一定條件的話),填滿一條cache-line,這個方式被稱作Streaming Load。
在程式為streaming方式運算處理的情況下,這樣的指令能非常顯著地提升了CPU從Write-Combining Buffer載入non-cacheable資料的效率
Intel給出的上圖就是採用和未採用Streaming Load的爆發傳輸性能對比,不過需要注意的是這裡的7000GB/s結果是採用雙執行緒+Streaming Load獲得的
(目前的x86處理器都能做Write-Combining,Wolfdale/Penryn的WB Buffer和K8一樣都是64位元組大小)
微架構改進——L2 Cache採用24路相聯度
我們知道,Cache是根據局部性原理(即最近被執行過的指令/資料很可能被再次使用以及位址相近的指令/資料很可能在一定的時間內被連續使用)而引入的,目的是把最可能經常重複使用的資料/指令保存在離CPU最接近的存儲層次中,縮短訪問主記憶體造成的CPU閒置等待
由於成本的原因,cache的大小總是有限的,CPU不可能100%都能在cache中找到所需的資料和指令,這也就會造成命中缺失,要降低缺失率,一般有以下辦法:
1、增加cache-line的容量
2、增加cache的容量
3、增加相聯度
4、引入路預測(例如Alpha 21264)和偽相聯(又被稱作列相聯)cache
5、透過編譯優化
6、透過並行或預取技術
Pentium M(Banias)、Core(Yonah)、Core 2(Merom/Penryn/Conroe/Wolfdale)的cache-line為64位元組,較它們的前輩Pentium III增加了一倍,容量方面更加是實現了1MB、2MB、4MB、6MB的提升
而在相聯度方面,Banias/Dothan/Yonah的L2 cache為8-way,Merom/Conroe為16-way(2MB L2的衍生版是8-way),擁有6MB L2 cache的Penryn/Wolfdale則是24-way相聯度
目前通用處理器L2 cache相聯度實作最高的紀錄應該是VIA的C7,有32-way......不過這看上去是一個完全為了節電而不是為了性能的選擇(C7只有128KB L2 cache)
組相聯是cache的記憶體位址映射三種方式之一,另外兩種映射方式為直接映射和全相聯
直接映射是最簡單的方式,每條cache-line都有固定對應的若干主記憶體位址
全相聯就是主記憶體中任何位址的資料都可以存放在cache中的任何一條cache-line裡
組相聯就是指數條cache-line被為安排一組,每組可以對應主記憶體中的若干固定位址
每組包含多少條cache-line,就是多少路相聯度,組相聯度越高,Cache的命中率就越高,不過要是不命中的話缺失代價也越高,因為搜索的時間會更長
Wolfdale/Penryn在L2 cache上透過更大的容量和更複雜的組相聯技術來保持較高的L2 Cache命中率,而晶片面積依然維持在比較合理的水準,這完全得益於45nm工藝,而只有4MB Cache的Q8200表現又將如何呢?