
在GTC 2012大會上,NVIDIA老總黃仁勳公佈了新一代Tesla加速卡的詳情,不過此次發布的Tesla顯卡算是雙胞胎,一款是基於雙芯GK104架構的Tesla K10,另外一款則使用了真正的新架構,基於GK110核心的Tesla K20。
K10和K20的特性有所不同,重點也不一樣

首先來看K10,它的物理外觀與GTX 690顯卡沒什麼區別,但是NVIDIA公佈的幾項參數耐人尋味, 單精度浮點能力為4.58TFLOPS,帶寬為320GB/s ,作為對比的是GTX 680單精度運算能力3.09TFLOPS,192GB/s帶寬,而GTX 690也有5.62TFLOPS,384GB/s帶寬,上一代Fermi核心浮點運算能力為1.58TFLOPS,帶寬192GB/s。
從參數上看,K10達到了NVIDIA所說的三倍於Fermi家族的單精度浮點能力,但是比GTX 680只提高了50%,帶寬也只高了了67%左右,明顯不如GTX 690顯卡。
由於是同樣的架構,Tesla K10很明顯在核心和顯存頻率上做了妥協,由於GK104架構的能效比很高,而HPC領域對功耗、發熱也不甚敏感,不知NVIDIA為何將K10的規格定的比GTX 690還低。
現場的圖片沒有公佈K10的顯存容量和TDP信息,但是GeForce GRID頁面出現的K520顯卡規格與K10一致,而顯存容量是8GB,TDP是250W,二者其實都是雙芯GK104顯卡,因此Tesla K10也是8GB顯存,250W TDP 。 (這個功耗低於GTX 690的300W,或許是規格降低唯一可能的解釋了)
Tesla K10現在就可以出貨,但是它並不是重點, 個人覺得它只是個過渡產品,扮演救火隊員的角色 ,因為GK104先天孱弱的雙精度運算能力注定了它不可能在HPC市場有多高的成就,NVIDIA之所以推GTX 690上陣是因為GK110架構來的比預期的還要晚。
GK110是NVIDIA針對高性能GPU計算市場開發的架構, 之前一直傳聞到今年8月份就會發布,但是NVIDIA給出的日期是今年第四季度 ,不論是28nm產能還是芯片自身的問題,這大半年的空白期總需要有人先頂上,這就是K10的使命了。
Tesla K20與GK110架構
NVIDIA對K20的描述是“3倍雙精度浮點性能”,並有Hyper-Q、Dynamic Parallelism等多種並行計算技術加持,這些是現有的GK104架構不具備的。
NVIDIA的PDF資料中介紹了GK110的SMX架構,也是192個CUDA核心

必須要承認,以前洩露的有關GK110架構的消息是錯誤的,GK110的SMX架構其實跟GK104還是一樣的,都是192個CUDA核心,32組SFU單元以及32個LD/ST單元。
GK110架構圖
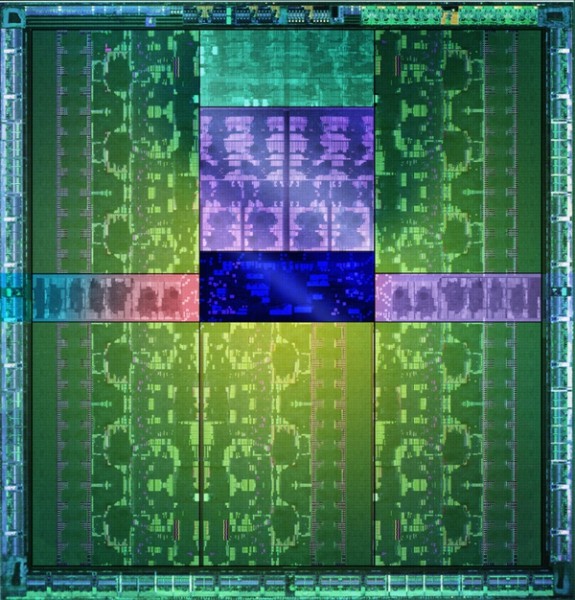
除去其他的功能單元之外,GK110核心總共有15組SMX單元,2880個CUDA核心, 但是Heise聲稱並非所有單元都是啟用的,實際上可能只有13-14組SMX單元,實際CUDA核心是2496或者2688個。
顯存位寬是384bit,已為黃仁勳和NVIDIA CTO確認 。 由於CUDA核心數已經低於之前的報導,顯存位寬降到384bit也是很自然的事,如果保持GK104的6Gbps顯存速率,那麼GK110的帶寬將達到288GB/s,終於超過AMD GCN架構的260GB /s了。
NVIDIA給出的3倍雙精度浮點性能不知是跟GF110顯卡還是跟GF110核心的Tesla加速卡做的比較,GF110的單精度浮點能力為1.58TFLOPS,顯卡中的雙精度為單精度的1/ 4,也就是0.4TFLOPS,但是GF110核心的Tesla卡雙精度能力可達單精度1/2,大約是0.8TFLOPS。
如此一來,如果以顯卡為基礎,GK110的雙精度浮點性能大約是1.2TFLOPS以上,如果是Tesla卡的3倍,那就是2.4TFLOPS以上,鑑於後者已經超出之前傳聞的2TFLOPS的能力, GK110的雙精度浮點能力應該是1.2TFLOPS或更高 。
Tesla K20配置了6pin+8pin供電接口

核心面積和TDP未知,不過K20配備的是6pin和8pin供電接口,最大TDP不會超過300W。 晶體管數量也是一個70億,準確點說是71億。
◆ GK110並行計算技術介紹
顯卡規格方面的信息基本就是這麼多了,再來看一下NVIDIA為GK110所增加的新技術吧。
Dynamic Parallelism(動態並行)
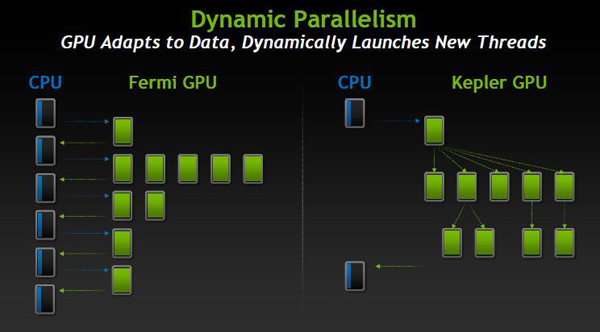
GK110架構的首要目標之一就是使程序員更方便地調用GPU強大的並行計算能力 。 傳統的模式下,GPU每次操作都需要CPU的參與,而Dynamic Paralleliom的存在使得GPU接收數據時會動態刷新線程而無需CPU參與。 由於內核有了獨立載入工作負載的能力,動態並行技術允許程序直接在GPU上運行。
這項技術的好處就是可以降低編程的複雜性,原本需要200-300行代碼才能完成的工作在GK110顯卡上只需要30行就可以了。
Hyper-Q
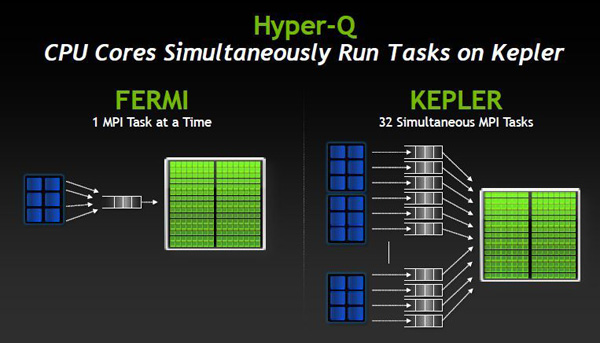
上一項技術強調的是簡化操作,是給CPU減負,而Hyper-Q則是增加了CPU同時載入工作的核心數,是在提升=高CPU的利用率,避免CPU過多的閒置。
Fermi架構中CPU只能同時運行一個MPI(Message Passing Interface消息傳遞接口)任務,但是在GK110架構中CPU同時運行的MPI任務數多達32個。
傳統的MPI任務主要基於多核CPU應用,與GPU強大的並行計算能力相比,CPU處理的MPI任務量實在是太小了,往往會帶來虛假的GPU依賴性,導致GPU的性能無法有效利用, Hyper-Q大幅提高了CPU可以分配給GPU的MPI任務量,如果同時傳遞32個任務給GPU,那麼理論性能會達到Fermi架構的32倍,實際應用中雖然不會這麼誇張,但是優化調度之後GPU的並行計算能力還是會有改善。
GPU Direct
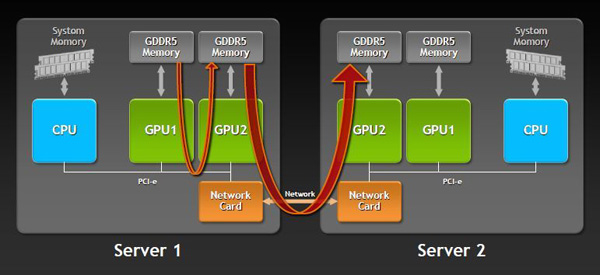
GPU Direct直連是NVIDIA官方PDF中沒有提到的,不過依然值得解釋一下。 NVIDIA已經推出了基於Kepler架構的GeForce GRID雲遊戲技術,那麼使用Kepler顯卡的服務器就免不了要互相交換數據。 GPU Direct技術可以讓服務器的中不同顯卡直接讀取顯存的數據,甚至不同服務器之間的顯卡也可以通過網卡讀取另一塊顯卡顯存中的數據,簡單來說就是提高了顯卡的數據交換能力,所需的步驟更少,延遲更低。
CUDA 5
要想使用上面介紹的技術就必須使用新的CUDA 5,GTC大會上NVIDIA已經發布了一個預覽版的CUDA 5 SDK,正式版將在今年三季度發布。
Kepler顯卡發布之後,Tesla家族也終於迎來架構更新,而且很快就會有更新架構的Tesla加速卡,得益於GK104良好的效能比,NVIDIA的Tesla加速卡也具備了這樣的能力,性能更強的同時功耗更低。
新一代GK110架構重點針對GPU計算性能做了加強,雙精度浮點能力提升到之前架構的三倍,並有動態並行、Hyper-Q、GPU Direct等技術輔助,無論是易用性還是性能都有明顯改善,擔當起GPU計算的光榮使命了。
來源:http://www.expreview.com/19535-all.html
K10和K20的特性有所不同,重點也不一樣
首先來看K10,它的物理外觀與GTX 690顯卡沒什麼區別,但是NVIDIA公佈的幾項參數耐人尋味, 單精度浮點能力為4.58TFLOPS,帶寬為320GB/s ,作為對比的是GTX 680單精度運算能力3.09TFLOPS,192GB/s帶寬,而GTX 690也有5.62TFLOPS,384GB/s帶寬,上一代Fermi核心浮點運算能力為1.58TFLOPS,帶寬192GB/s。
從參數上看,K10達到了NVIDIA所說的三倍於Fermi家族的單精度浮點能力,但是比GTX 680只提高了50%,帶寬也只高了了67%左右,明顯不如GTX 690顯卡。
由於是同樣的架構,Tesla K10很明顯在核心和顯存頻率上做了妥協,由於GK104架構的能效比很高,而HPC領域對功耗、發熱也不甚敏感,不知NVIDIA為何將K10的規格定的比GTX 690還低。
現場的圖片沒有公佈K10的顯存容量和TDP信息,但是GeForce GRID頁面出現的K520顯卡規格與K10一致,而顯存容量是8GB,TDP是250W,二者其實都是雙芯GK104顯卡,因此Tesla K10也是8GB顯存,250W TDP 。 (這個功耗低於GTX 690的300W,或許是規格降低唯一可能的解釋了)
Tesla K10現在就可以出貨,但是它並不是重點, 個人覺得它只是個過渡產品,扮演救火隊員的角色 ,因為GK104先天孱弱的雙精度運算能力注定了它不可能在HPC市場有多高的成就,NVIDIA之所以推GTX 690上陣是因為GK110架構來的比預期的還要晚。
GK110是NVIDIA針對高性能GPU計算市場開發的架構, 之前一直傳聞到今年8月份就會發布,但是NVIDIA給出的日期是今年第四季度 ,不論是28nm產能還是芯片自身的問題,這大半年的空白期總需要有人先頂上,這就是K10的使命了。
Tesla K20與GK110架構
NVIDIA對K20的描述是“3倍雙精度浮點性能”,並有Hyper-Q、Dynamic Parallelism等多種並行計算技術加持,這些是現有的GK104架構不具備的。
NVIDIA的PDF資料中介紹了GK110的SMX架構,也是192個CUDA核心
必須要承認,以前洩露的有關GK110架構的消息是錯誤的,GK110的SMX架構其實跟GK104還是一樣的,都是192個CUDA核心,32組SFU單元以及32個LD/ST單元。
GK110架構圖
除去其他的功能單元之外,GK110核心總共有15組SMX單元,2880個CUDA核心, 但是Heise聲稱並非所有單元都是啟用的,實際上可能只有13-14組SMX單元,實際CUDA核心是2496或者2688個。
顯存位寬是384bit,已為黃仁勳和NVIDIA CTO確認 。 由於CUDA核心數已經低於之前的報導,顯存位寬降到384bit也是很自然的事,如果保持GK104的6Gbps顯存速率,那麼GK110的帶寬將達到288GB/s,終於超過AMD GCN架構的260GB /s了。
NVIDIA給出的3倍雙精度浮點性能不知是跟GF110顯卡還是跟GF110核心的Tesla加速卡做的比較,GF110的單精度浮點能力為1.58TFLOPS,顯卡中的雙精度為單精度的1/ 4,也就是0.4TFLOPS,但是GF110核心的Tesla卡雙精度能力可達單精度1/2,大約是0.8TFLOPS。
如此一來,如果以顯卡為基礎,GK110的雙精度浮點性能大約是1.2TFLOPS以上,如果是Tesla卡的3倍,那就是2.4TFLOPS以上,鑑於後者已經超出之前傳聞的2TFLOPS的能力, GK110的雙精度浮點能力應該是1.2TFLOPS或更高 。
Tesla K20配置了6pin+8pin供電接口
核心面積和TDP未知,不過K20配備的是6pin和8pin供電接口,最大TDP不會超過300W。 晶體管數量也是一個70億,準確點說是71億。
◆ GK110並行計算技術介紹
顯卡規格方面的信息基本就是這麼多了,再來看一下NVIDIA為GK110所增加的新技術吧。
Dynamic Parallelism(動態並行)
GK110架構的首要目標之一就是使程序員更方便地調用GPU強大的並行計算能力 。 傳統的模式下,GPU每次操作都需要CPU的參與,而Dynamic Paralleliom的存在使得GPU接收數據時會動態刷新線程而無需CPU參與。 由於內核有了獨立載入工作負載的能力,動態並行技術允許程序直接在GPU上運行。
這項技術的好處就是可以降低編程的複雜性,原本需要200-300行代碼才能完成的工作在GK110顯卡上只需要30行就可以了。
Hyper-Q
上一項技術強調的是簡化操作,是給CPU減負,而Hyper-Q則是增加了CPU同時載入工作的核心數,是在提升=高CPU的利用率,避免CPU過多的閒置。
Fermi架構中CPU只能同時運行一個MPI(Message Passing Interface消息傳遞接口)任務,但是在GK110架構中CPU同時運行的MPI任務數多達32個。
傳統的MPI任務主要基於多核CPU應用,與GPU強大的並行計算能力相比,CPU處理的MPI任務量實在是太小了,往往會帶來虛假的GPU依賴性,導致GPU的性能無法有效利用, Hyper-Q大幅提高了CPU可以分配給GPU的MPI任務量,如果同時傳遞32個任務給GPU,那麼理論性能會達到Fermi架構的32倍,實際應用中雖然不會這麼誇張,但是優化調度之後GPU的並行計算能力還是會有改善。
GPU Direct
GPU Direct直連是NVIDIA官方PDF中沒有提到的,不過依然值得解釋一下。 NVIDIA已經推出了基於Kepler架構的GeForce GRID雲遊戲技術,那麼使用Kepler顯卡的服務器就免不了要互相交換數據。 GPU Direct技術可以讓服務器的中不同顯卡直接讀取顯存的數據,甚至不同服務器之間的顯卡也可以通過網卡讀取另一塊顯卡顯存中的數據,簡單來說就是提高了顯卡的數據交換能力,所需的步驟更少,延遲更低。
CUDA 5
要想使用上面介紹的技術就必須使用新的CUDA 5,GTC大會上NVIDIA已經發布了一個預覽版的CUDA 5 SDK,正式版將在今年三季度發布。
Kepler顯卡發布之後,Tesla家族也終於迎來架構更新,而且很快就會有更新架構的Tesla加速卡,得益於GK104良好的效能比,NVIDIA的Tesla加速卡也具備了這樣的能力,性能更強的同時功耗更低。
新一代GK110架構重點針對GPU計算性能做了加強,雙精度浮點能力提升到之前架構的三倍,並有動態並行、Hyper-Q、GPU Direct等技術輔助,無論是易用性還是性能都有明顯改善,擔當起GPU計算的光榮使命了。
來源:http://www.expreview.com/19535-all.html