
NVIDIA 在 GTC 大會上正式發布了 Pascal 顯卡的旗艦 Tesla P100,
雖然今年1月份的CES展會上 NVIDIA 發布的 Drive PX2 自動駕駛平台使用的也是 Pascal 顯卡,
但當時的發布只是象徵性,現在才是首次曝光 GP100 顯卡,擁有3584個CUDA核心,153億個晶體管,
16GB HBM2記憶體,核心頻率高達1328MHz,浮點性能10.6TFLOPS。

Pascal 顯卡有些規格與爆料相符,不過很多內容也是出乎意外的,
可以確定的內容是16nm FinFET、16GB HBM 2 、4096bit頻寬以及支援NVLink總線等,
不過 GP100 的CUDA核心數比之前曝光的要少很多,只有3584個,
比目前 GM200 核心的3072個沒高出多少,不過 GP100 的雙精度CUDA單元暴增,而且核心時脈高,
基本時脈就有1328MHz,Boost為1480MHz,比很多Maxwell顯卡的超頻頻率都要高。

GP100核心規格
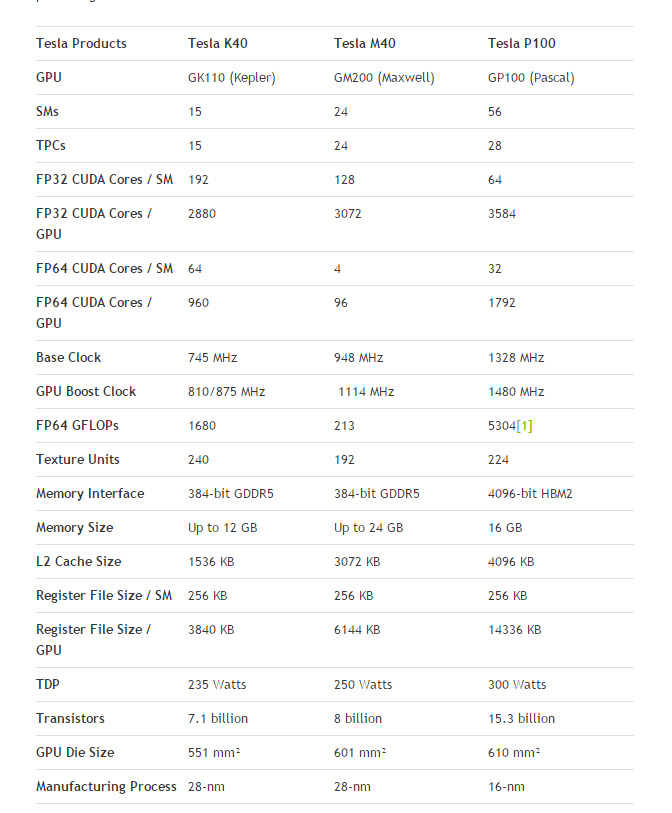
GP100 核心主要是為高效能計算而生的,雖然3584個CUDA核心相比目前 GM200 的3072個提升不多,
但在FP64雙精度單元上,GP100 核心總計擁有1792個CUDA核心,相當於FP32單精度的1/2,
相比之下 GM200 只有96個,所以其FP64雙精度性能高達5.3TFOPS,
而 GM200 核心只有0.213TFLOPS,GK110 核心也只有1.68TFLOPS,絕對是碾壓之姿。
GP100 第二點變化是升級了記憶體架構,從之前的GDDR5變成了HBM 2,
從圖片上看也是堆棧了4顆HBM 2,等效頻寬4096bit,不過時脈1.4Gbps而非HBM 2應有的2Gbps,
因此帶寬只有720GB/s,並沒有達到之前所說的TB/s級別,
只不過720GB/s的帶寬已經遠遠超過了之前 GM200 / GK110 核心的240-288GB/s帶寬了。
GP100 核心更讓人驚訝的地方是核心頻率,Pascal 使用了更先進的16nm FinFET(之前說高效能的16nm Plus),
新製程帶來的好處不僅是功耗和發熱降低,核心時脈也大幅提升了,
之前 GK100 / GM200 這樣的大核心 GPU 頻率通常在1GHz內,
甚至為了控制功耗還會降低到500-700MHz左右,但 GP100 基礎時脈就有1328MHz,Boost 1480MHz。
GP100核心架構
核心架構方面,GP100核心總計使用了56組SM單元,28組TPC單元,
依然是每組SM單元64個CUDA核心,因此總計3584個CUDA核心,
但不同以往的是這次的雙精度單元回來了,每組SM單元中還有32個FP64雙精度單元。
GP100核心的SM單元架構

除了CUDA單元數量增加,GP100為了適應高性能計算還大幅增加了快取及寄存器大小,
L2從GM200的3072KB增加到了4096KB,每組SM單元的寄存器文件大小還是256KB,
但總數從6144KB增加到了14336KB。
GP100核心架構示意圖

GP100 還有一個重要技術就是NVLink總線,其帶寬遠高於PCI-E總線,不過這個更偏向HPC領域,
對消費級市場影響最大的可能就是在NVLink總線支援下,8-Way SLI 顯卡互聯也是可能的。
以上是 GP100 核心的一些簡要資訊,GP100 顯卡主要面向專業領域,
對應的消費級產品應該是 GTX Titan X 的接任,但目前還沒有什麼消息,即便有這價格也可想而知的驚人。
至於主流市場的 GP104 核心則要等到今年6月的電腦展。



來源:http://www.expreview.com/46481.html
雖然今年1月份的CES展會上 NVIDIA 發布的 Drive PX2 自動駕駛平台使用的也是 Pascal 顯卡,
但當時的發布只是象徵性,現在才是首次曝光 GP100 顯卡,擁有3584個CUDA核心,153億個晶體管,
16GB HBM2記憶體,核心頻率高達1328MHz,浮點性能10.6TFLOPS。
Pascal 顯卡有些規格與爆料相符,不過很多內容也是出乎意外的,
可以確定的內容是16nm FinFET、16GB HBM 2 、4096bit頻寬以及支援NVLink總線等,
不過 GP100 的CUDA核心數比之前曝光的要少很多,只有3584個,
比目前 GM200 核心的3072個沒高出多少,不過 GP100 的雙精度CUDA單元暴增,而且核心時脈高,
基本時脈就有1328MHz,Boost為1480MHz,比很多Maxwell顯卡的超頻頻率都要高。
GP100核心規格
GP100 核心主要是為高效能計算而生的,雖然3584個CUDA核心相比目前 GM200 的3072個提升不多,
但在FP64雙精度單元上,GP100 核心總計擁有1792個CUDA核心,相當於FP32單精度的1/2,
相比之下 GM200 只有96個,所以其FP64雙精度性能高達5.3TFOPS,
而 GM200 核心只有0.213TFLOPS,GK110 核心也只有1.68TFLOPS,絕對是碾壓之姿。
GP100 第二點變化是升級了記憶體架構,從之前的GDDR5變成了HBM 2,
從圖片上看也是堆棧了4顆HBM 2,等效頻寬4096bit,不過時脈1.4Gbps而非HBM 2應有的2Gbps,
因此帶寬只有720GB/s,並沒有達到之前所說的TB/s級別,
只不過720GB/s的帶寬已經遠遠超過了之前 GM200 / GK110 核心的240-288GB/s帶寬了。
GP100 核心更讓人驚訝的地方是核心頻率,Pascal 使用了更先進的16nm FinFET(之前說高效能的16nm Plus),
新製程帶來的好處不僅是功耗和發熱降低,核心時脈也大幅提升了,
之前 GK100 / GM200 這樣的大核心 GPU 頻率通常在1GHz內,
甚至為了控制功耗還會降低到500-700MHz左右,但 GP100 基礎時脈就有1328MHz,Boost 1480MHz。
GP100核心架構
核心架構方面,GP100核心總計使用了56組SM單元,28組TPC單元,
依然是每組SM單元64個CUDA核心,因此總計3584個CUDA核心,
但不同以往的是這次的雙精度單元回來了,每組SM單元中還有32個FP64雙精度單元。
GP100核心的SM單元架構
除了CUDA單元數量增加,GP100為了適應高性能計算還大幅增加了快取及寄存器大小,
L2從GM200的3072KB增加到了4096KB,每組SM單元的寄存器文件大小還是256KB,
但總數從6144KB增加到了14336KB。
GP100核心架構示意圖
GP100 還有一個重要技術就是NVLink總線,其帶寬遠高於PCI-E總線,不過這個更偏向HPC領域,
對消費級市場影響最大的可能就是在NVLink總線支援下,8-Way SLI 顯卡互聯也是可能的。
以上是 GP100 核心的一些簡要資訊,GP100 顯卡主要面向專業領域,
對應的消費級產品應該是 GTX Titan X 的接任,但目前還沒有什麼消息,即便有這價格也可想而知的驚人。
至於主流市場的 GP104 核心則要等到今年6月的電腦展。
來源:http://www.expreview.com/46481.html
