NVIDIA (輝達) 今天宣布推出 Pascal™ 架構深度學習平台的最新生力軍 NVIDIA® Tesla® P4 及P40 GPU 加速器與全新軟體,在效能及速度提供大幅度的提升以加速人工智慧服務的推論生產作業負載。

語音助理、待過濾垃圾郵件及電影與產品推薦引擎等現代人工智慧 (AI) 服務越來越複雜,與一年前的神經網路相比需要高出10倍的運算。目前以CPU為主的技術無法提供現代人工智慧服務所需要的即時回應能力,導致不佳的使用者經驗。
Tesla P4及P40 特別針對推論設計,使用經訓練的深度神經網路識別語音、影像及文字以回應使用者和裝置要求。Pascal架構 GPU具備以8位元 (INT8) 運算為主的專門推論指令,提供比CPU快45倍的反應速度(1),與不到一年前推出的GPU解決方案相比則提升了4倍(2)。
Tesla P4 為資料中心帶來最高的能源效率,其小尺寸及最小50瓦特的低功率設計可安裝於任何伺服器內,讓生產作業負載推論的能源效率達 CPU 的 40 倍(3)。在進行視訊推論作業負載(4)時,單一伺服器裡安裝單顆 Tesla P4 即可取代 13 台僅採用 CPU 的伺服器;而包含伺服器及用電量的總持有成本則能節省達8倍。
Tesla P40為深度學習作業負載帶來最大的處理量。一台搭載 8 顆 Tesla P40 加速器的伺服器擁有每秒47兆次運算 (TOPS) 的推論效能及 INT8 指令,可取代 140 台以上的 CPU 伺服器的效能(5)。若以每台 CPU 伺服器約 5,000 美元計算,可節省 65 萬美元以上的伺服器採購成本。
NVIDIA加速運算總經理Ian Buck表示:「有了 Tesla P100 以及新推出的 Tesla P4及P40,NVIDIA為資料中心提供唯一的端對端深度學習平台,為各大產業釋放龐大的人工智慧潛力。將訓練時間從數天大幅縮短至數小時,能立即解析資料,並透過人工智慧服務即時對消費者做出回應」。
實現更快速推論的軟體工具
另外與 Tesla P4 及 P40 推出的包含兩項加速人工智慧推論的創新軟體:NVIDIA TensorRT 及 NVIDIA DeepStream SDK。
TensorRT為針對優化生產部署所設計的深度學習模型函式庫,具有立即回應極度複雜網路的能力。透過訓練過的 32 位元或 16 位元定義神經網路以及設定以降低精度的INT8運算為目的進行優化,將深度學習應用的處理量及效率極大化。
NVIDIA DeepStream SDK銜接強大的Pascal伺服器,與雙 CPU 只能處理7個串流(6)的運算能力相比,能即時同步解碼並分析高達 93 個 HD 視訊串流。這解決人工智慧的其中一項重大挑戰:處理大規模的影音內容分析以應用到如自駕車、互動式機器人、過濾及廣告投放等領域。深度學習整合至視訊應用中讓企業能提供前所未有、智慧且創新的視訊服務。
協助客戶向前邁進
NVIDIA的客戶提供越來越多需要最高運算效能的創新人工智慧服務。其中台灣廠商廣達持續在伺服器業務與 NVIDIA 合作,從世上首座人工智慧超級電腦系統 DGX-1、Facebook Big Sur 推論伺服器到搭載 NVIDIA 糖果盒大小 Tesla P4 輕巧 1U 伺服器,皆透過該公司而得以打造出優異的產品陣容。
NVIDIA 共同創辦人暨執行長黃仁勳表示:「廣達從早期便與我們一同致力於GPU伺服器發展,不論想建造何種類型資料中心,透過我們與廣達及雲達的合作都能達成。」
雲達科技總經理楊晴華表示:「我們的客戶相當倚重雲達在超大規模 、高密度融合機架式等級解決方案中的領導地位,這些解決方案通常都需要高效能的作業負載。以深度學習的應用而言,平行運算回應之間的延遲性表現十分重要,而 Tesla P40 和 P4 正是能表現出準確與靈敏效能的新一代 GPU 解決方案。」
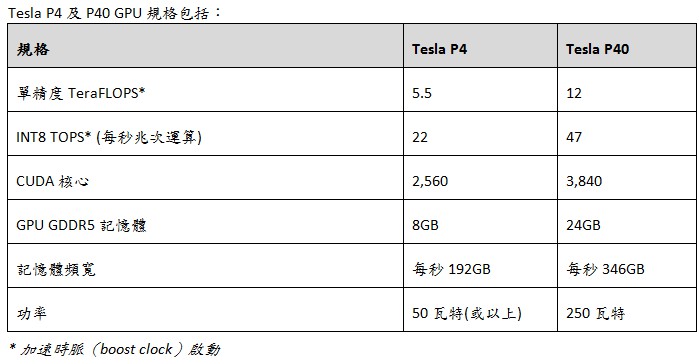
規格
供貨時程
NVIDIA Tesla P4及P40 分別預定於11月及10月由各大ODM、OEM及通路合作夥伴供貨。
語音助理、待過濾垃圾郵件及電影與產品推薦引擎等現代人工智慧 (AI) 服務越來越複雜,與一年前的神經網路相比需要高出10倍的運算。目前以CPU為主的技術無法提供現代人工智慧服務所需要的即時回應能力,導致不佳的使用者經驗。
Tesla P4及P40 特別針對推論設計,使用經訓練的深度神經網路識別語音、影像及文字以回應使用者和裝置要求。Pascal架構 GPU具備以8位元 (INT8) 運算為主的專門推論指令,提供比CPU快45倍的反應速度(1),與不到一年前推出的GPU解決方案相比則提升了4倍(2)。
Tesla P4 為資料中心帶來最高的能源效率,其小尺寸及最小50瓦特的低功率設計可安裝於任何伺服器內,讓生產作業負載推論的能源效率達 CPU 的 40 倍(3)。在進行視訊推論作業負載(4)時,單一伺服器裡安裝單顆 Tesla P4 即可取代 13 台僅採用 CPU 的伺服器;而包含伺服器及用電量的總持有成本則能節省達8倍。
Tesla P40為深度學習作業負載帶來最大的處理量。一台搭載 8 顆 Tesla P40 加速器的伺服器擁有每秒47兆次運算 (TOPS) 的推論效能及 INT8 指令,可取代 140 台以上的 CPU 伺服器的效能(5)。若以每台 CPU 伺服器約 5,000 美元計算,可節省 65 萬美元以上的伺服器採購成本。
NVIDIA加速運算總經理Ian Buck表示:「有了 Tesla P100 以及新推出的 Tesla P4及P40,NVIDIA為資料中心提供唯一的端對端深度學習平台,為各大產業釋放龐大的人工智慧潛力。將訓練時間從數天大幅縮短至數小時,能立即解析資料,並透過人工智慧服務即時對消費者做出回應」。
實現更快速推論的軟體工具
另外與 Tesla P4 及 P40 推出的包含兩項加速人工智慧推論的創新軟體:NVIDIA TensorRT 及 NVIDIA DeepStream SDK。
TensorRT為針對優化生產部署所設計的深度學習模型函式庫,具有立即回應極度複雜網路的能力。透過訓練過的 32 位元或 16 位元定義神經網路以及設定以降低精度的INT8運算為目的進行優化,將深度學習應用的處理量及效率極大化。
NVIDIA DeepStream SDK銜接強大的Pascal伺服器,與雙 CPU 只能處理7個串流(6)的運算能力相比,能即時同步解碼並分析高達 93 個 HD 視訊串流。這解決人工智慧的其中一項重大挑戰:處理大規模的影音內容分析以應用到如自駕車、互動式機器人、過濾及廣告投放等領域。深度學習整合至視訊應用中讓企業能提供前所未有、智慧且創新的視訊服務。
協助客戶向前邁進
NVIDIA的客戶提供越來越多需要最高運算效能的創新人工智慧服務。其中台灣廠商廣達持續在伺服器業務與 NVIDIA 合作,從世上首座人工智慧超級電腦系統 DGX-1、Facebook Big Sur 推論伺服器到搭載 NVIDIA 糖果盒大小 Tesla P4 輕巧 1U 伺服器,皆透過該公司而得以打造出優異的產品陣容。
NVIDIA 共同創辦人暨執行長黃仁勳表示:「廣達從早期便與我們一同致力於GPU伺服器發展,不論想建造何種類型資料中心,透過我們與廣達及雲達的合作都能達成。」
雲達科技總經理楊晴華表示:「我們的客戶相當倚重雲達在超大規模 、高密度融合機架式等級解決方案中的領導地位,這些解決方案通常都需要高效能的作業負載。以深度學習的應用而言,平行運算回應之間的延遲性表現十分重要,而 Tesla P40 和 P4 正是能表現出準確與靈敏效能的新一代 GPU 解決方案。」
規格
供貨時程
NVIDIA Tesla P4及P40 分別預定於11月及10月由各大ODM、OEM及通路合作夥伴供貨。