
Habana Gaudi2於訓練熱門的電腦視覺和NLP模型時,
展現出相較Nvidia A100 2倍的吞吐量效能
展現出相較Nvidia A100 2倍的吞吐量效能
在Intel Vision中,英特爾公司旗下的Habana Labs推出Gaudi®2處理器,這是用於訓練的第2代Gaudi®處理器,並針對推論部署推出即將上市的Greco處理器,其為Goya™處理器的後續產品。這些處理器專為AI深度學習應用而設計,建立在Habana的高效率架構之上並採用7nm製程打造,能夠在資料中心當中,針對電腦視覺與自然語言處理的模型訓練與推論效能,提供客戶更高的效能。
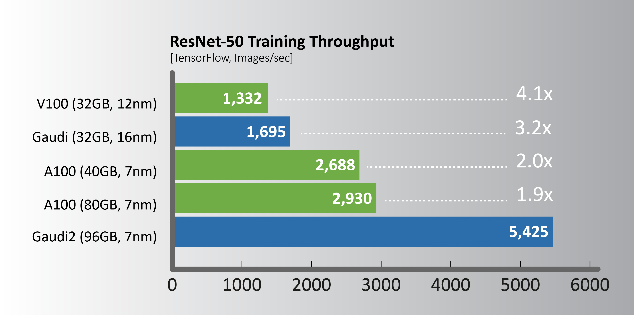
活動當下,Habana展示Gaudi2於電腦視覺—ResNet-50(v1.1)和自然語言處理—BERT Phase-1和Phase-2的訓練吞吐量效能,其工作負載量幾乎是Nvidia A100 80GB處理器的2倍。
更多內容:關於Habana® Gaudi®2的更多資訊,包含推出新聞等,請造訪Intel Newsroom、Habana 訓練解決方案、Habana Gaudi2白皮書 和深入研究Habana® Gaudi®處理器影片。
Gaudi2:專為深度學習訓練所設計

對於資料中心客戶而言,資料集和AI工作負載的規模和複雜性不斷提升,讓訓練深度學習模型工作越來越耗費時間與成本。Gaudi2的設計,能夠為雲端運算和企業現場的客戶,帶來改良後的深度學習效能與效率。
為提升模型的準確性和時近性(recency),客戶需要更頻繁的訓練。根據IDC的資料,於2020年接受調查的機器學習(ML)從業者當中,74%的人對他們的模型進行5到10次的訓練迭代,超過50%的人每週或是更頻繁地重新建立模型,超過26%的人每日甚至每小時就重建模型。56%的受訪者認為,他們的組織汲取AI所能提供的洞察力、創新和強化終端使用者體驗,訓練成本為其最大障礙。Gaudi平台解決方案包含第1代Gaudi和Gaudi2,專為解決這項日益成長的需求而誕生。
更多內容:觀賞更多客戶和合作夥伴說明Gaudi2的深度學習優勢,請造訪我們的網站。
為深度學習而生,如今更提升至新境界
Habana Gaudi2處理器顯著地提升訓練效能,其建立在同樣高效率的第1代Gaudi架構之上,讓客戶在雲端使用Amazon EC2 DL1執行個體,以及在現場使用Supermicro Gaudi Training Server 時,相較現有的GPU解決方案,其價格效能比值要高出40%。
從第1代Gaudi到Gaudi2,架構上的進步包含:
- 製程技術從16nm提升至7nm
- 導入新的資料類型,包含在Matrix Multiplication Engine(MME)和Tensor Processor Core 運算引擎當中的FP8
- Tensor Processor Core從8個提升至24個
- 為了卸載主機子系統的負擔,晶片整合媒體處理引擎
- 封裝記憶體容量從32GB變為3倍至96GB,HBM2E頻寬達2.45TB/sec
- 雙倍SRAM容量達48MB
- 為了在產業標準上提供高效率的垂直擴充(scale-up)和水平擴充(scale-up),內建的RDMA over Converged Ethernet(RoCE2)從整合10個NIC提升至24個。
100% AI設計,200%效能表現
希望增加訓練時間和營運效率的客戶,藉由立即可用(out-of-the-box)的各項訓練指標來評估深度學習的效能和價值。在Intel Vision,Habana向客戶展現相對於市場上其它領先解決方案,Gaudi2處理器的效能。下列圖表是熱門的電腦視覺和自然語言處理模型的訓練結果,與其它解決方案所公布的指標比較。
相較使用相同製程節點的A100 GPU,Gaudi2提供明顯的訓練效能領先幅度,下列關鍵工作負載所展示的效能比較約為2倍,其中包含與框架一同整合的全套軟體。這些結果顯示出專門設計的Gaudi2深度學習加速框架,從根本上而言更具效率。
電腦視覺 – ResNet-50
自然語言處理 – BERT
結合Phase-1和Phase-2的有效吞吐量
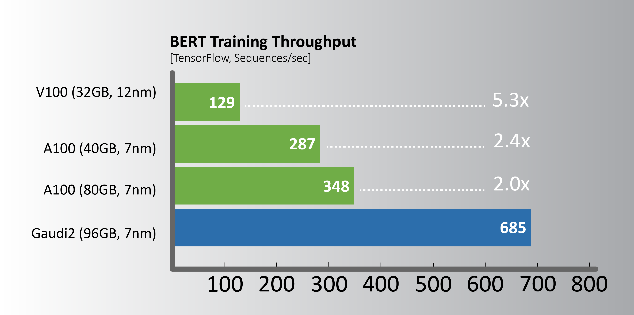
工作負載和組態詳細資訊,請造訪 intel.com/performanceindex 的Vision章節。您的結果可能有所不同。
自然語言處理 – BERT
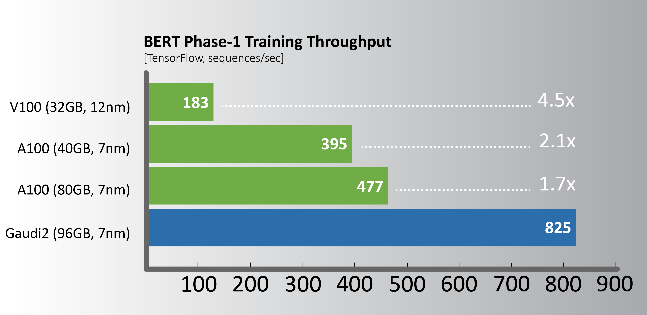
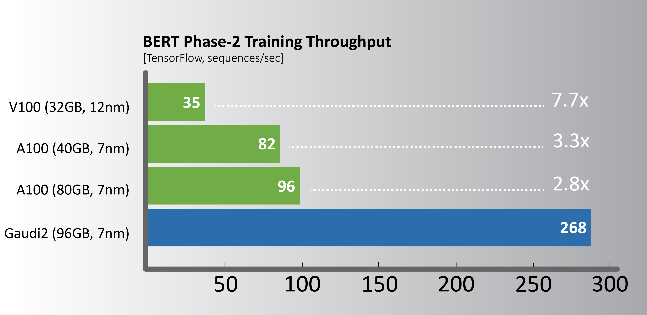
工作負載和組態詳細資訊,請造訪intel.com/performanceindex 的Vision章節。您的結果可能有所不同。
網路容量、靈活性、效率
每個Gaudi2處理器都整合了24個100-Gigabit RoCE連接埠,顯著地放大訓練頻寬。
垂直擴充:每個Gaudi2所具備的21個連接埠,專門用來連結內含8張HLS-Gaudi®2伺服器內部的其它7個處理器,採用全速連結、無阻塞組態。
水平擴充:每個處理器所具備的3個連接埠,專門用於水平擴充,於8張Gaudi伺服器提供2.4Tbps的網路吞吐量。
符合OCP OAM標準:為了簡化客戶的系統設計,Habana提供符合OCP規格的Universal Baseboard(UBB)標準產品。
方便且靈活使用:藉由在晶片上整合產業標準RoCH,客戶能夠輕鬆地擴展和配置Gaudi2系統,符合他們的深度學習叢集需求,能夠從1個Gaudi2擴展至數千個。
建立系統選擇:透過在廣泛使用的產業標準乙太網路連結性上打造系統,Gaudi2讓客戶可以從一系列乙太網路交換器和相關網路設備中進行選擇,進而節省成本。
整合效率:晶片整合網路介面控制器(NIC)連接埠,顯著地降低整體零件成本。
HLS-Gaudi2伺服器
除了內含8片Gaudi2之外,HLS-Gaudi2伺服器還配備雙插槽Intel® Xeon®可擴充處理器子系統。 Habana提供此類伺服器讓客戶評估Gaudi2,同時與系統OEM合作,為終端客戶的部署帶來市場解決方案。
Gaudi2資料中心的進展
迄今為止,在以色列的Habana Gaudi2資料中心已部署1000台HLS-Gaudi2,用來支援Gaudi2軟體最佳化的研發,並為即將推出的Gaudi®3處理器的近一步發展提供參考。
更多內容:欲使用Habana Gaudi2打造深度學習訓練系統,詳見影片。
獲取Habana Gaudi2解決方案: Habana正在跟Supermicro合作,將於2022年第3季在市場上推出Supermicro Gaudi®2 Training Server。更與DDN®合作,提供包含Supermicro伺服器的一站式解決方案伺服器,並與DDN AI400X2儲存解決方案相互搭配達成擴增AI儲存。
簡化模型建立與遷移:滿足開發者需求
為了支援客戶將工作負載和系統,從現有的 GPU模型轉換至Gaudi®2,並協助他們保留軟體開發的投資,Habana SynapseAI® Software Suite針對深度學習工作負載最佳化,專為簡化模型建立和遷移所設計。為了滿足深度學習開發者的需求,SynapseAI整合TensorFlow和PyTorch框架,並提供超過30種熱門的電腦視覺和自然語言參考模型。開發者可以從Habana Developer Site取得文件、方法內容和社群支援等相關資訊,並在Habana GitHub 上提供參考模型和模型路線圖。
更多內容:深入了解關於Gaudi®和Gaudi®2的開發者支援,請造訪Habana Developer Site。





