
前言:
有「Father of Zen」之稱的 Mike Clark ( AMD's Corporate Fellow Silicon Design Engineer) 和 Mahesh Subramony (Senior Fellow Design Engineer)於近日對 AMD Zen 5架構之 AVX512、Zen 5c做了更深入的解析

⇧AMD's Corporate Fellow Silicon Design Engineer Mike Clark (the Father of Zen)
Mike Clark提到,AMD的 Zen 5和緊湊型 Zen 5c核心旨在實現高性能和能源效率,包括設計目標
效能
• 再次實現 1T與 2T效能的重大提升
• 未來運算的新基礎
• 512位元資料路徑上的 AVX512可提高吞吐量和 AI提升
平台支援
• 提供「Zen 5」和「Zen 5c」(緊湊型)核心變體
• 支援可設定的 FP512/FP256資料路徑
• 支援擴展和能源效率
• 支援 4nm和 3nm
• 增強的 ISA功能

AMD的 Zen 5架構透過 512位元路徑、AVX 512負載和雙倍 L2到 L1頻寬提升運算能力,支援每個核心兩個執行緒,新一代分支預測器、雙埠 iCache、6k指令、雙埠資料快取、12路關聯性、每週期 8次操作、每週期 6次浮點操作、FADD減少到 2個週期

AMD的 Zen 5架構將跨越 4nm和 3nm製程節點,為下一代 AMD整個 CPU產品堆疊提供動力,涵蓋從桌上型電腦和行動 PC到資料中心的 EPYC處理器,設計一個有凝聚力的底層架構來滿足所有這些市場的需求是一項令人難以置信的工程壯舉
Mike提到 AMD並將於本月底推出 4nm Zen 5晶片處理器,但尚未公佈 3nm變體的時間表,Mike進一步闡述了同時為 4nm和 3nm製程設計 Zen 5的挑戰,Mike稱這兩個版本基本上是「相互疊加」的
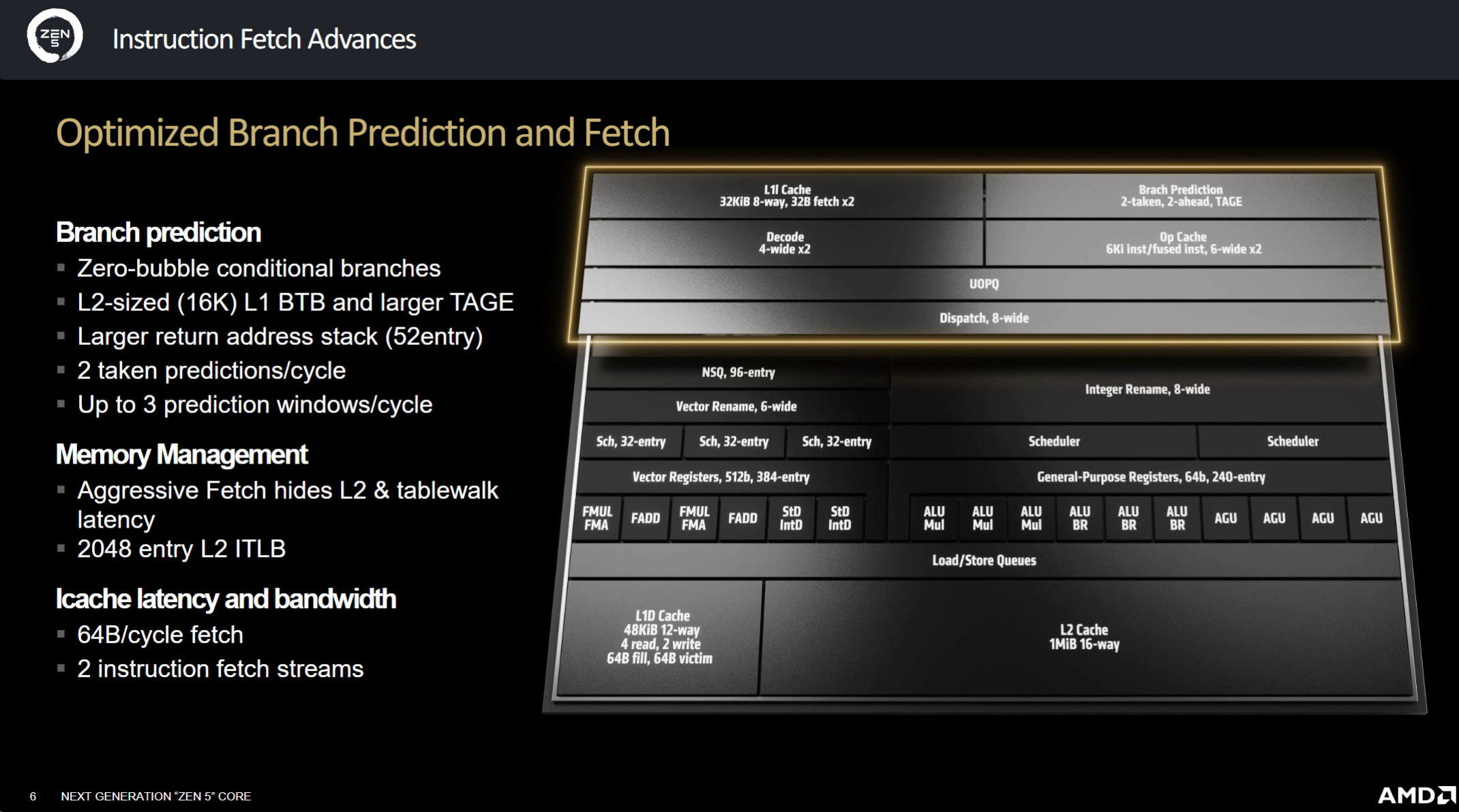
Mike說 AMD使用其緊湊型 Zen 5c核心(與 Intel的 E Core類似的專為後台任務設計的較小核心)來降低筆記型電腦處理器的成本並提高效能,然而與競爭對手不同的是,AMD尚未將這些核心引入其桌面產品線,緊湊型 Zen 5c核心標誌著 AMD緊湊型核心的第二次迭代,但目前尚未計劃用於 Ryzen 9000系列,不過未來的 Ryzen桌上型處理器則將採用緊湊型 Zen 5c核心,並且拓展至獨特實現的技術

Zen 5之加載儲存單元將其從 3D增加到 48K,採用 12路設計,同時保持較低的延遲
AMD並已將其 TLBs(高速緩存)的大小增加到 96個條目,並進行了其他改進以優化效能
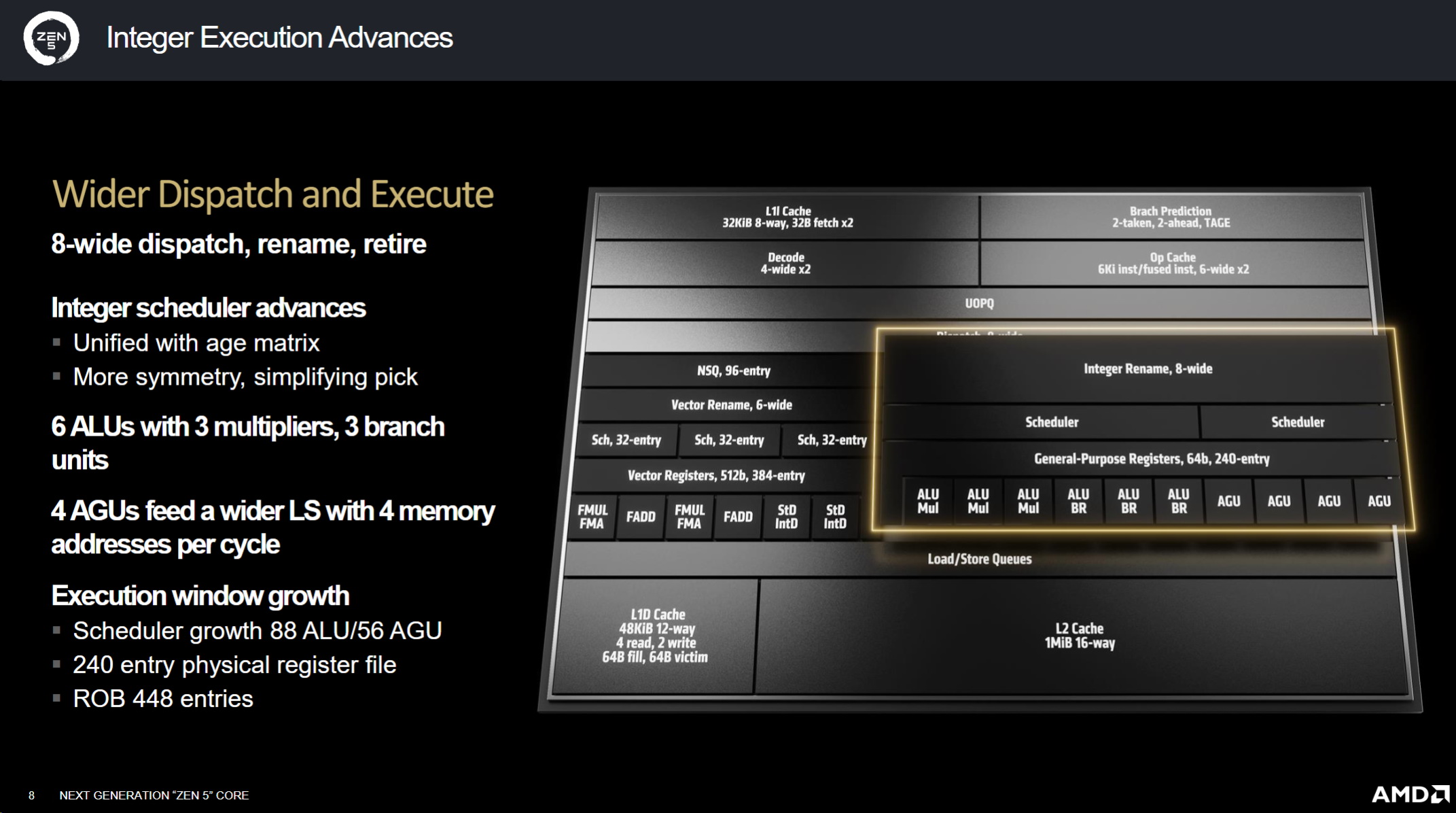
眾所皆知,Intel放棄了對高性能 AVX-512指令注入硬體加速支持,但 AMD的 Zen 5則標誌著 Ryzen系列全面支援 AVX-512的加速,與 Intel不同的是,Intel在處理器運行 AVX-512工作負載時必須降低頻率速度,而 AMD的 AVX-512指令集則將以相同的頻率速度來運作標準整數運算, Mike也詳細介紹了該公司如何實現這一壯舉,並表示其 Zen 5c核心也可以運行完整的 AVX-512,AMD並提高了分支預測能力,增加了 L1的規模,並增強了階段能力
AMD的新處理器具有更有效率的調度接口,可以前饋更多指令,Op-cache現在儲存的是指令而不是操作,並且可以將兩個指令融合為一個,Zen 5架構透過並行解碼兩個管道、在 T模式下為每個執行緒專用一個管道以及使用寬調度來退出 8個指令來提高效能,AMD進行了一些更改,以提高處理器指令分配的效率和對稱性,從而實現更精簡的調度
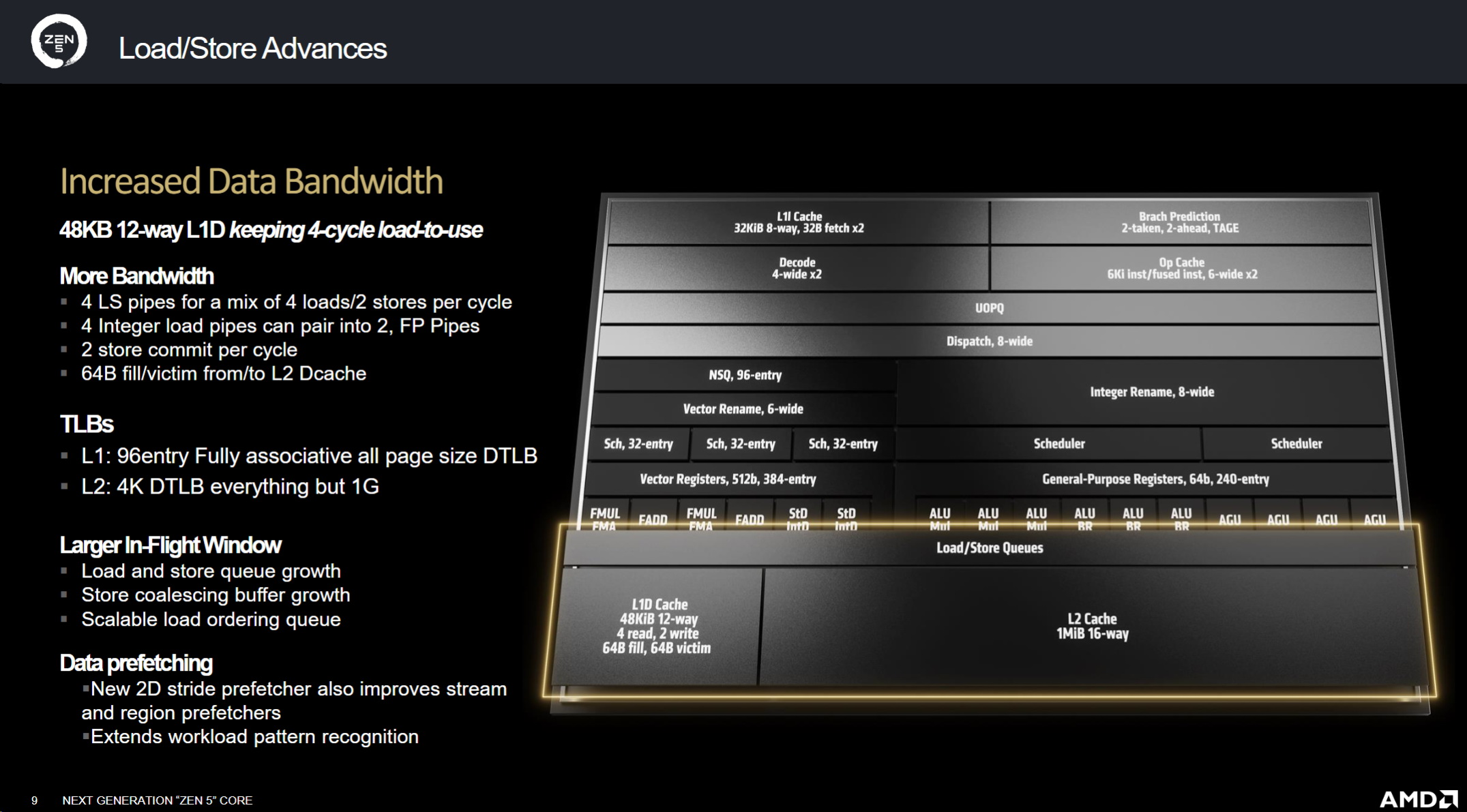
透過優化執行管道以及使用 FMA、F-moles和 FP進行整數存儲,將浮點性能提高了 33%,同時增加了調度程序以適應資料成長,將實體暫存器檔案增加了一倍
AMD的目標是透過將其分成更小的區塊、自然地降低功耗以及對所有核心使用相同的 IPC和 ISO來優化其設計,他們還可以安排節能核心進行多執行緒工作,或使用經典複合體進行低功耗工作,強大的 IPC可以在調度錯誤時快速反應並修正

Zen 5引入了新指令 ISA,包括 AVX512,用於繞過快取的直接儲存以支援 VP2相交,從而在 VE編碼中啟用 VNNI

AMD的目標是在未來工作負載的平衡基礎上提高運算能力,而 Zen 5做到了這點,Zen 5核心的單核心效能比 Zen 4核心快了 40%,Zen 5架構與 Zen 4架構相比,IPC會有 15%的提升,基於 Zen 5架構的處理器在頻率上還會有拉升,Zen 5架構改進的部分還包括:
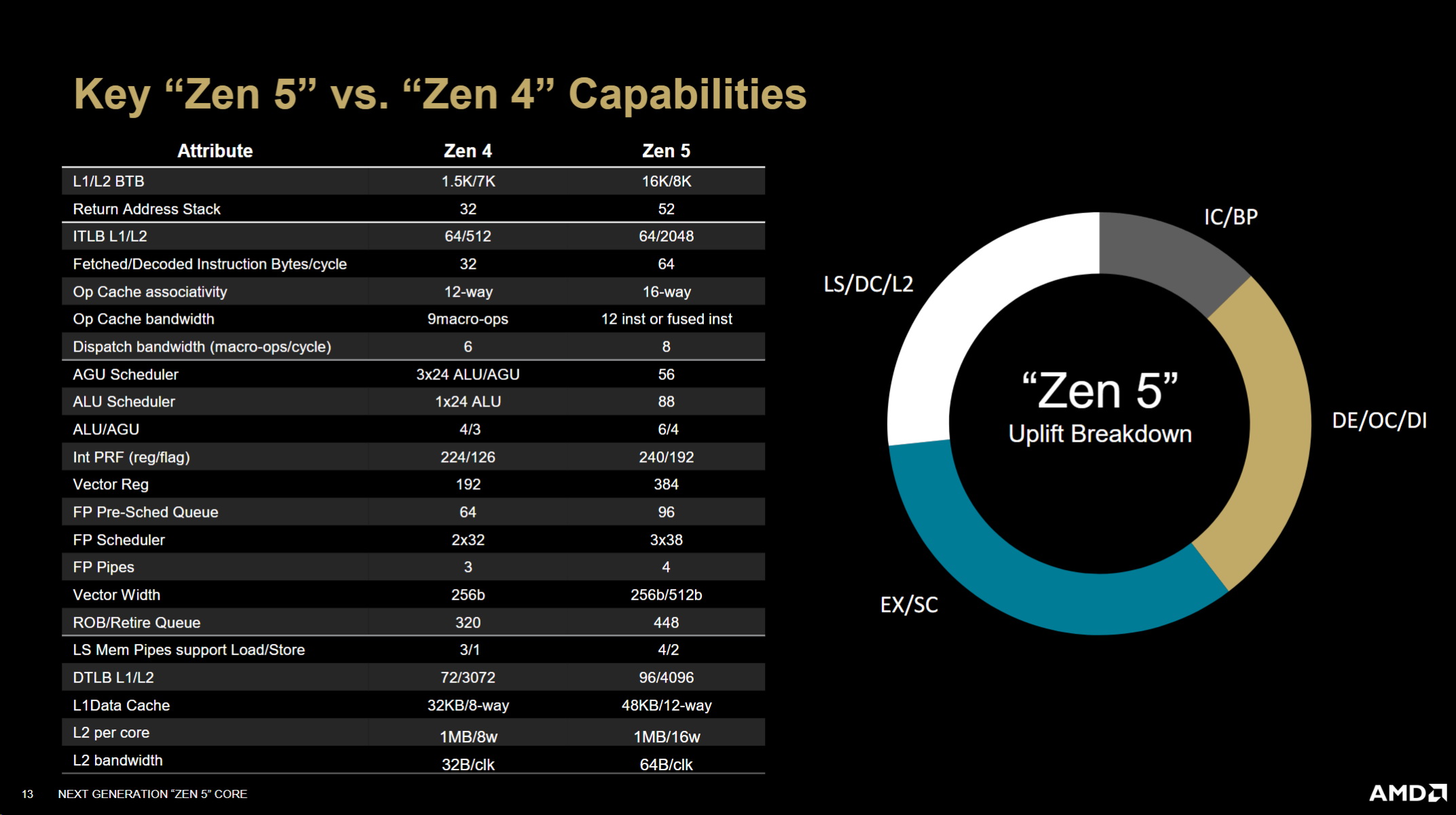
我們將 L2關聯性從 8路增加了一倍到 16路,我們將 L2到 L1 的頻寬從 32位元組增加了一倍到 64 位元組,L3 一點延遲,但我們現在實際上可以在 L3 中實現 320次飛行中的失誤,並且具有 Zen 4之前的所有優點,其中 L2快速且私密
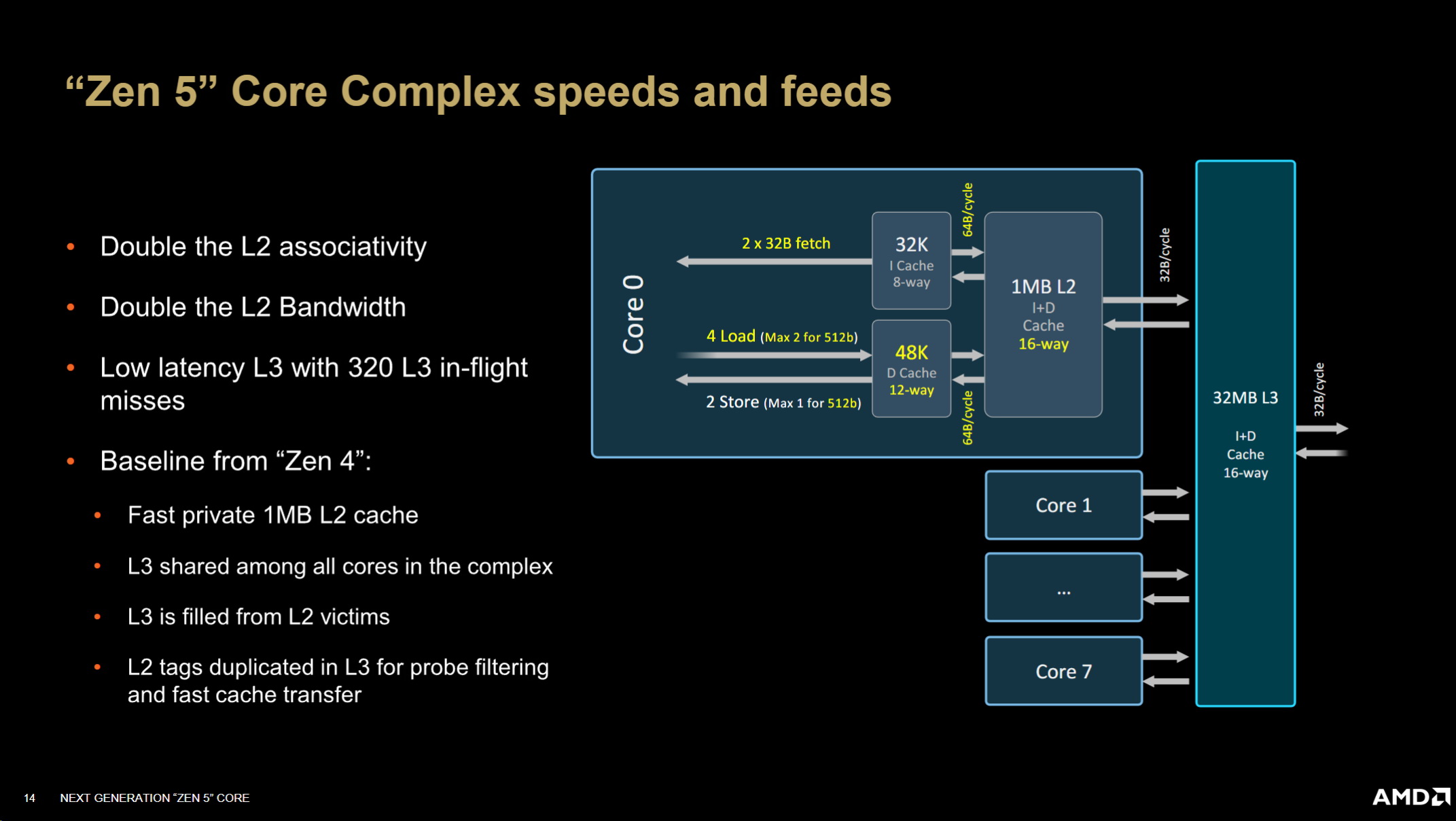
L3和 L2在複合體內共用,因此我們獲得了 L3和 L2的全部容量,我認為我們將這些核心運行到客戶端空間的 SOC中,包括行動和桌面部分,這就是我們在這裡所做的事情,但正如我們所說,Zen繼續發展 Zen5核心複合體,最後一級會有 N個核心
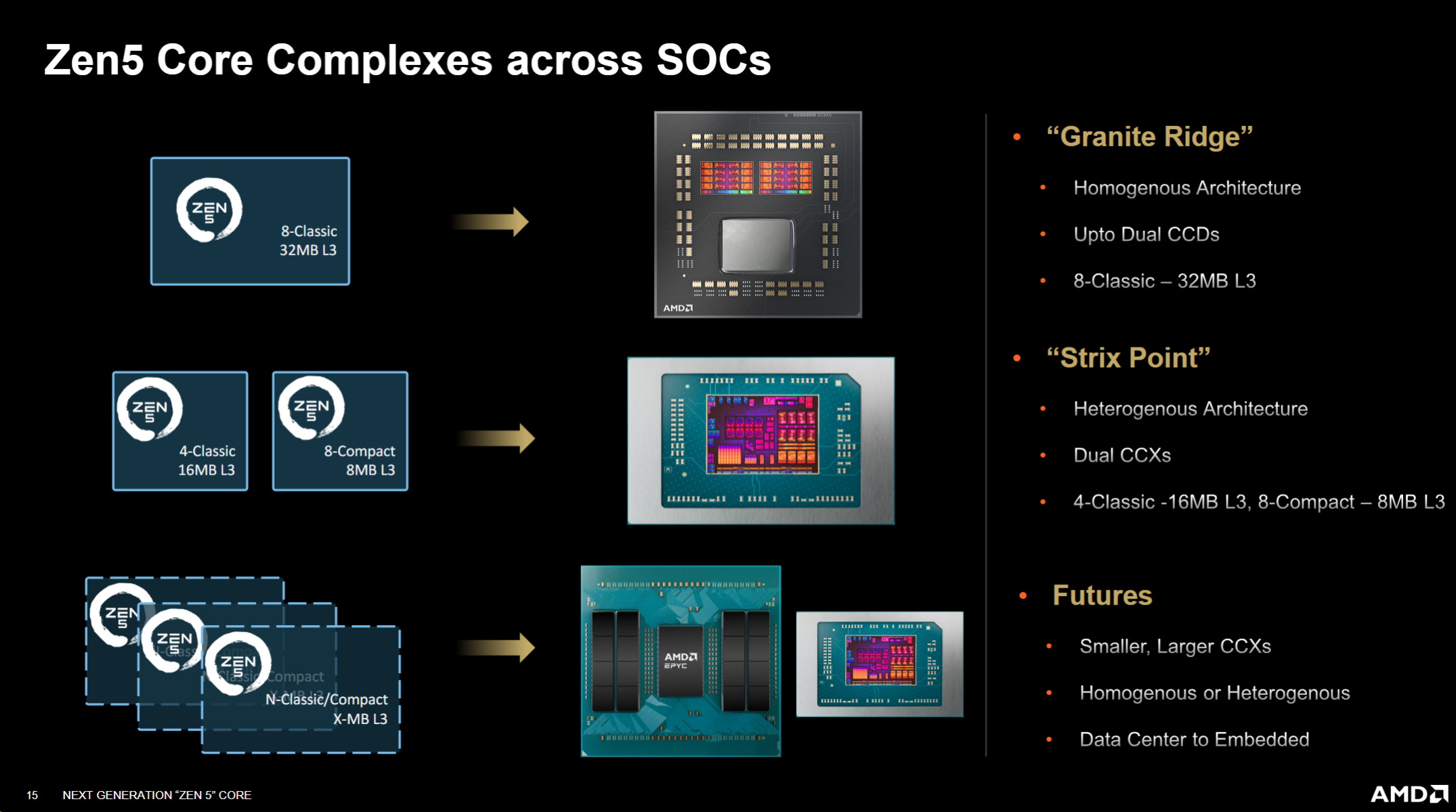
Strix Point SOC架構圖解析
Mahesh Subramony說 : 展望未來,正如 Mark所指出的,將會有一部以 Zen課程為基礎的史詩,並且將會有更小、更大的 CCX,它們將在從客戶端到嵌入到中間的所有內容中發揮作用。因此,我們可以使用同質、異質複合體來申請 HSOC,並且您將看到許多基於 Zen 5的產品
多年來我們的堆疊中。因此,快速瀏覽一下您所看到的,Zen 5兩個核心複合體,一個在 B,兩個核心,16個在 B,8個在 B,有兩個核心複合體,在數據中,這六個 CX中的每一個,每個週期 32字節,讀取和寫入,進入無限結構,進入 GPU,你有一個 HWGPR16、CU、RDNA 3.5引擎,這就是問題類型,糾正一下,那就是 RDNA 3.5,每個週期透過四個 32個位元組、四個圖形連接到資料結構,工作負載對頻寬更加敏感,整個,允許它利用大數據路徑對我們來說至關重要
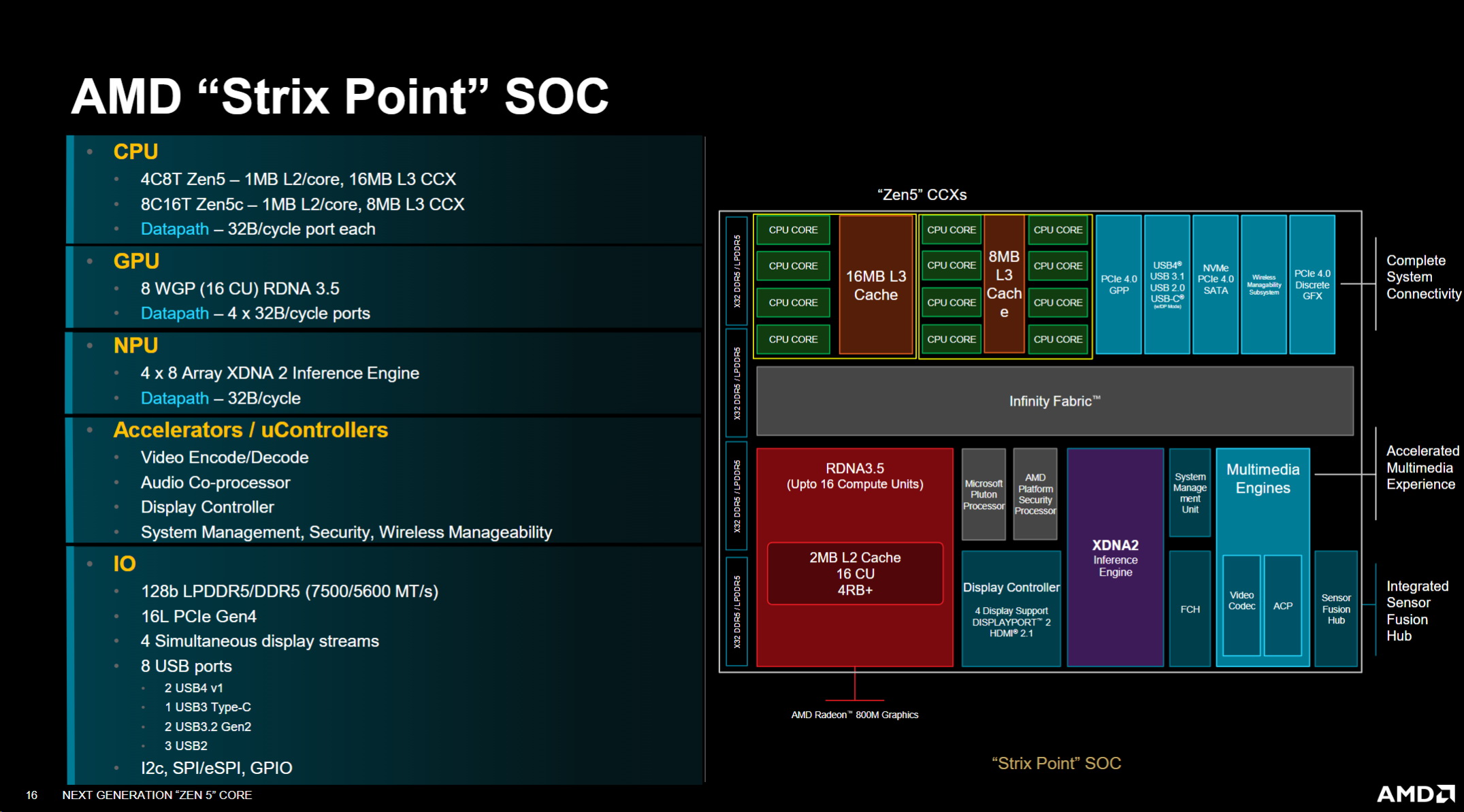
第三個是計算,NPU具有 XDNA 2推理引擎的 4×8陣列,並且還透過每週期 32位元組的資料連接埠連接到 infrasy結構。
,除此之外,我們還有一些加速器和微控制器,我們早些時候在 APU方面談到了這一點,另一方面,進一步改進我們所有的加速器和微控制器。視訊編碼解碼、音訊編碼處理都是為了效率。再次顯示控制器以實現同時顯示。而且你有系統管理,一堆微控制器管理電源、安全性、可管理性,以及我們需要管理的某些 I/O的單獨控制器,因此,需要一些全面的微控制器來幫助協調系統內的系統管理功能,然後,當我們關注 I/O時,再次看到 128位元 LP5/D5組合,LP上每秒 7,500兆傳輸,DDR5上每秒 5,600兆傳輸,PCIe Gen4的 16通道。我知道有一次會議提出了將車道從 20條減少到 16條的問題
在功率方面,我們注意到從系統的角度來看,額外的完整通道被用於輔助存儲,你知道它沒有太多的連接,因此,我們從二級儲存中去除了我們所擁有的一點額外的靈活性,我們將再次重新審視這一點。但在本例中,我們將這些通道從第四代 20通道的熱點減少到 16通道
USB 3.2 C型、兩個 USB 3.2 A型端口和三個額外的 USB 2端口,用於我們認為該 SOC所需的所有連接,當然,其他 GPIO、A2C是由 eSpy開發的
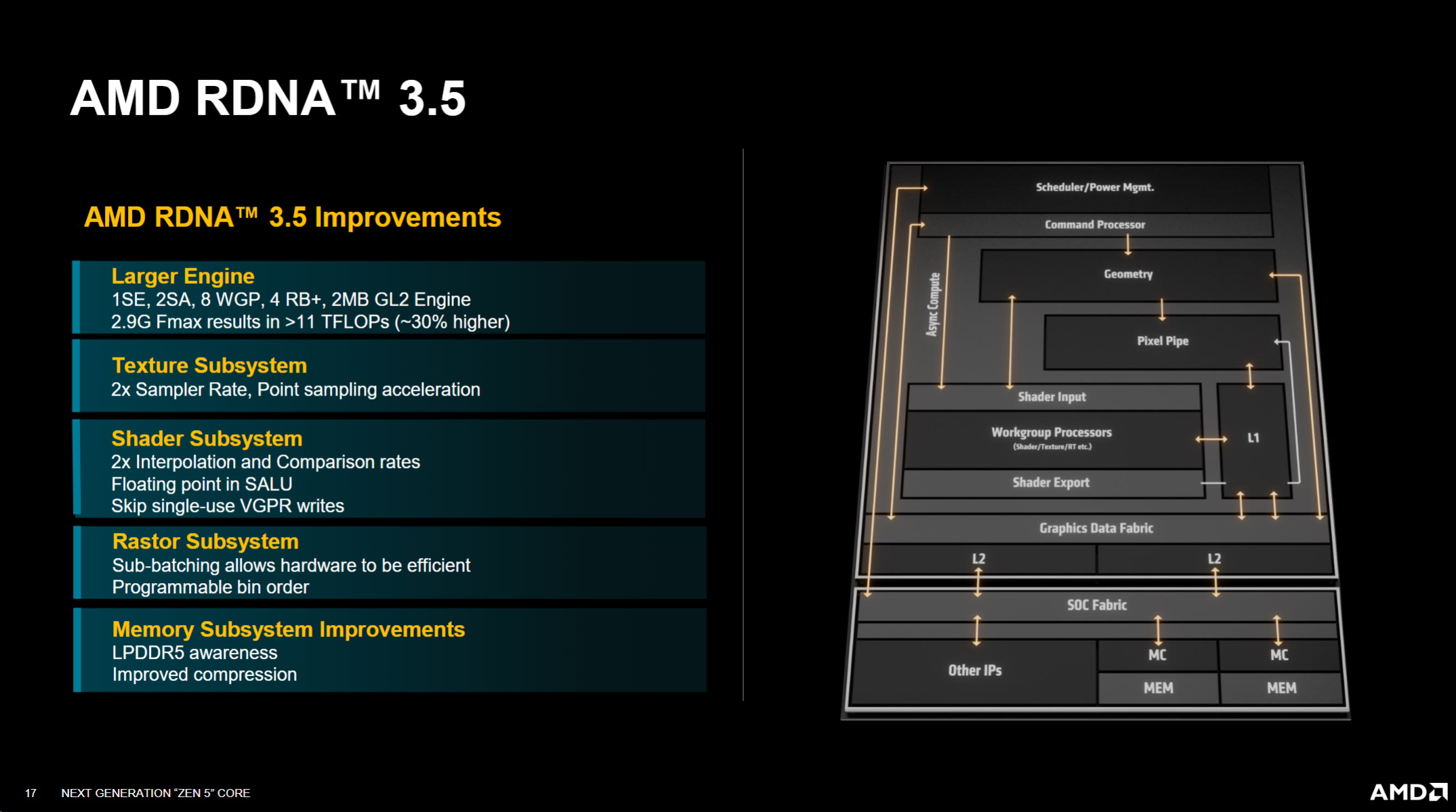
RDNA 3.5架構圖解析
再次快速深入了解 RDNA 3.5的改進內容, RDNA 3.5它不是架構改進的世代跳躍。我想確保這一點很清楚,正如 Mike所提到的,根據我們與移動朋友的合作關係,我們可以從這個引擎中獲得功率效率的擠壓。因此,將一些效率帶入引擎是主要的驅動力,但我們沒有安裝更大的發動機,所以驅動這些效率使我們能夠安裝更大的發動機,所以它是一個 AWGP發動機,老實說,這是一個更大的引擎,這就是我們在這裡獲得大部分性能提升的方式。但同樣,從每瓦功率性能和每比特性能的角度來看,我們所取得的效率使我們能夠將該引擎壓縮到我們擁有的較小的 TDP預算中。因此,從紋理子系統的角度快速接觸一些子系統,以及我們的雙倍速率上一些最常見的紋理採樣操作的範例子集
現在可以以某種特定的通用格式並行處理一個 PM2D紋理的兩個四邊形樣本。所以這對於一些常見的遊戲紋理操作來說是一個顯著的加速。點採樣加速,因此硬體可以偵測到平點採樣的使用,並將這些採樣操作引導到更快、功耗更低的處理部分,從而再次節省功耗。我想我們確實注意到這裡是一個減壓軸,因此,新的硬體允許多個請求 ALU通道透過解壓縮器共享相同紋理的輸出。這允許 GPU透過關閉一些未使用的解壓縮器來節省電力,文本子系統中的小技巧使我們能夠從系統中獲得這種效率。從著色器子系統的角度來看,同樣是兩個 x插值和比較率。其中,你知道,插值的向量化和現在比較是雙重評級的,這兩種操作在圖形區域中都很常見,標量 ALU中支援浮點,因此這提高了任何需要浮點的波統一計算的效率,在某些圖形技術中開始變得更加常見。所以我們加入了這一點,Mike談到了這個新的 SAALU 指令,它告訴著色器處理器它可以跳過一次性 VGPR,立即使用或使用一次然後丟棄的結果。因此,RDNA 3.5現在允許硬體檢測到這一點並將結果直接轉發到後續指令,從而跳過該指令。所以所有這些改變都可以提高效能和效率,快速進入柵格子系統。是的,所以 RDNA 3處理幾何圖形和批次以最大限度地減少外部內存,3.5向前邁出了一步,它增加了將這些批次分成更小的子批次的支援。因此,這使得硬體總體上更加高效,特別是在需要批量進給處理時。這變得非常有幫助。它還添加了可編程的 bin順序。因此,這增加了新批次的第一個 bin是先前批次的最後一個 bin的可能性,因此本質上所有這些都驅動時間局部性減少外部記憶體存取量,對嗎?正如 Mike所提到的,時間和空間局部性。同樣,每比特的性能,推動了更高能效的底線
任何最終內存子系統的改進,LP-DDR5的運作方式與 G略有不同,因此請注意這一點並獲得更多開啟頁面的點擊率,從而提高效率並改善壓縮。您知道,在圖形渲染期間,通常需要編寫顏色渲染目標,然後將其附加到幀的不同部分的讀取/寫入,所以 DNA 3.5提高了能力更頻繁地進行正確操作,以便稍後可以對其進行解壓縮,從而提高整體記憶體壓縮,然後將這種效率提高到系統
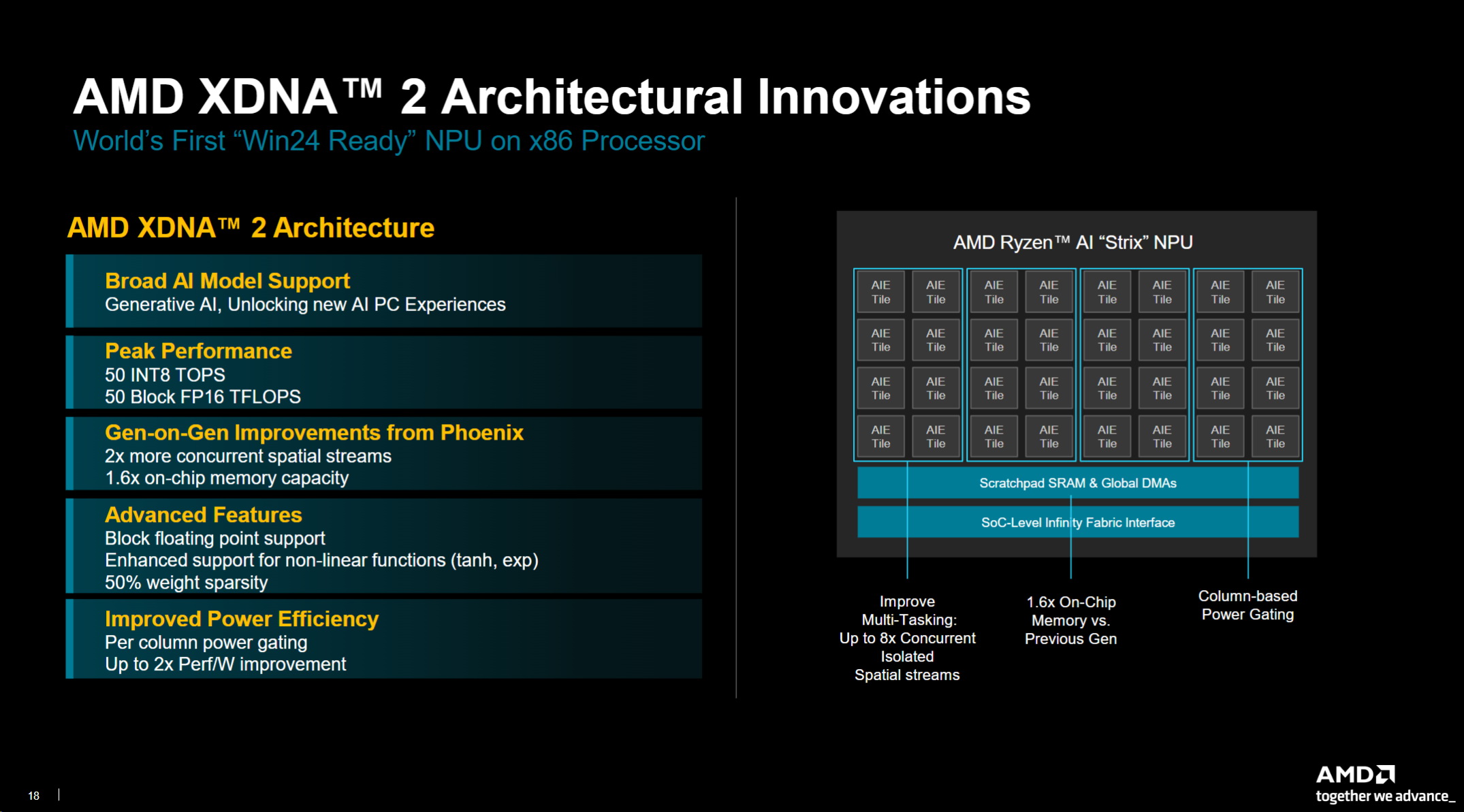
XDNA 2架構圖解析
我將詳細介紹 XDNA 2,但只要抓住這裡的關鍵點,就可以廣泛支援 AI模型,我們談到的血統是能夠為多代設計這些引擎,並將這種經驗帶到這裡。它是一台可配置的機器。它具有能夠的靈活性,它適應未來不斷發展的模型,可以利用並發性,從峰值效能的角度來看,它有 15個大的下降,可以阻止流量,我們談到的 FB16,8位元的吞吐量,但精度為 16,同樣,資料類型非常重要並推動這一點。我認為您會看到我們的許多競爭對手也將開始朝這個方向前進,試圖在您獲得這種效率的資料類型中找到更高的效率,對右翼群體產生良好影響,所以我認為我們正在破土動工,並讓人們更多地了解其準確性,而不僅僅是關心峰頂,我認為隨著這個領域的不斷發展,我們將對此有更多的了解
一代又一代,我認為這只是兩個 X以上的並發空間流,更多的內存,腳堤上的容量,那些引擎,同樣在每個圖塊的基礎上,我們也將 MAC增加了一倍,您也可以透過這種方式擁有引擎,以及 50%的權重稀疏性和增強的對非線性函數的支持。所以這一切都只是這些機器的傳統中汲取的設計可以提高能源效率,擁有像這樣的大型引擎並且無法提取電源效率,或者如果它可能是一種犯罪,當我們達到能夠限制效果和應用程式在列或列對上運行的程度時,能夠為門供電這些附加列完全完整,並且具有僅針對該用例需要點亮的資料路徑,我認為它會取得成果,現在,我們將所有內容都放在一個通用引擎上,將這種計算視為具有大記憶體的單一計算,儘管這種設計可以透過我們的自適應網格互連演變為看起來像這樣,我們擁有最後一級記憶體的方式以及我們如何管理它,我們可以讓它看起來像那個大型引擎。我認為我們已經承擔了增加這種靈活性的一些負擔,您相信,隨著軟體發展到始終在後台運行並且只需要該引擎的一個子集來滿足這些要求,它將取得成果
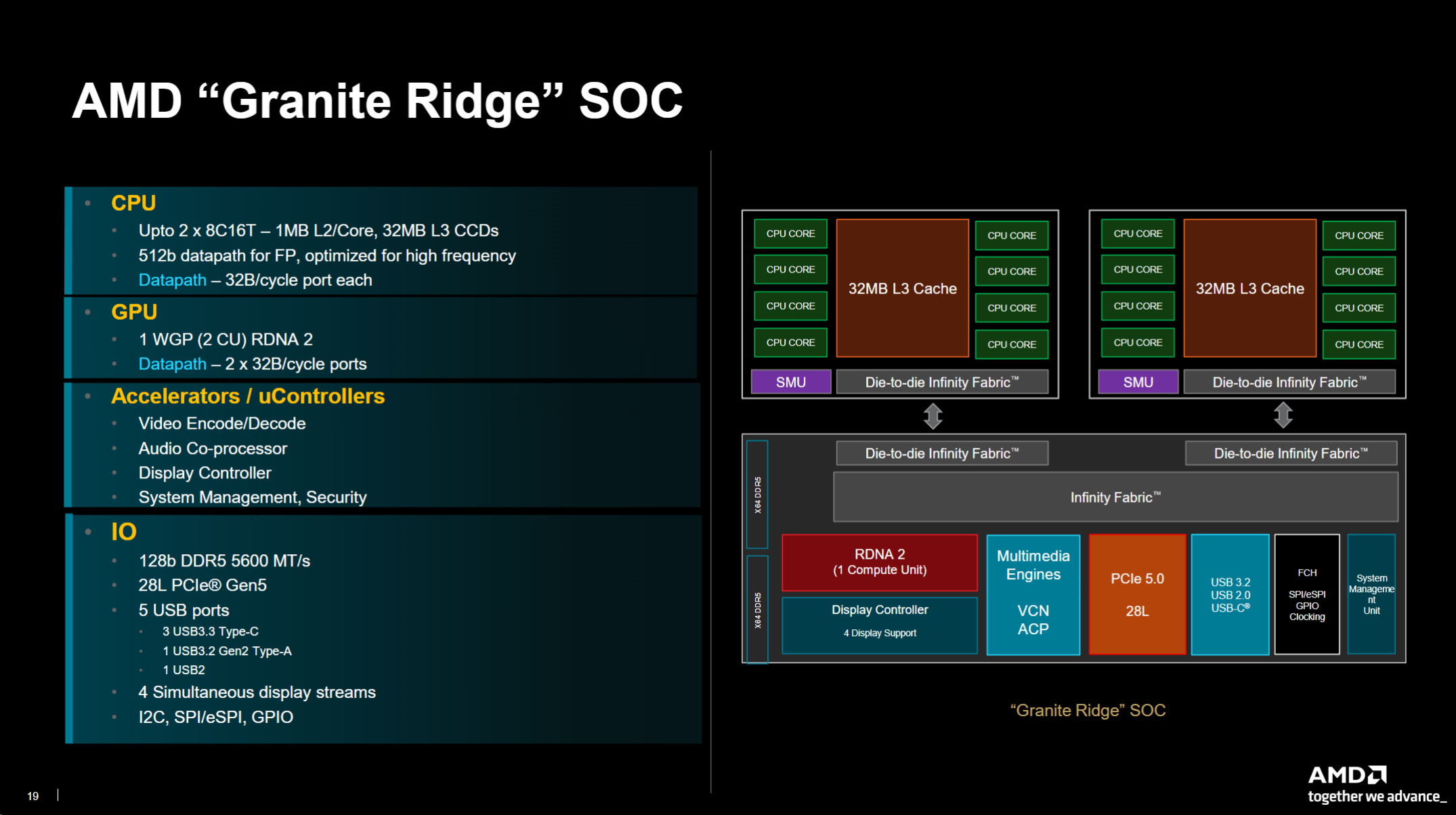
Granite Ridge SOC架構圖解析
我們推出的下一個 SOC是 Granite Ridge SOC,最多兩個 8個核心 16個線程複合體,每個核心 1MB和 2個 CCD,每個 CCD 32MB L3。正如 Mike 所提到的,FB的 5核位資料路徑,但同樣從我們的製程節點角度以及高頻設計的角度來看,該核心都經過了最佳化。每個連接埠的資料路徑為每個週期 32位元組,因此每個 CCD都有進入 I/O晶片的資料路徑。 GPU維持不變,如果你願意的話,確實需要配置來照亮這個地方,而且,由於引擎精簡,它的資料也更小,每個週期只有兩個 32位元組連接埠進入記憶體。它確實具有視訊編碼解碼、音訊處理器和顯示控制器以及系統管理和安全性,就像上一代一樣。在 I/O方面,同樣是 128位元 DDR5、28條 PCIe Gen5通道,以及 5個 USB端口,其中三種類型為 C型,然後再次連接 USB 2 連接埠,可以支援同步顯示流,並擁有 I2C、spy 和 GPIO所需的所有 I/O。因此,從 I/O晶片的角度來看,我們完全使用了上一代的產品,使我們能夠適應 AM5,CCB的尺寸確實增加了,以提供 IPC和性能改進,Mike談到了這一點,但是然後封裝前端能夠將更大的 CCD安裝到相同的 AM5基礎架構中,以便使用者可以從下一代的平台重用中受益,這也是我們未來的關鍵設計目標
從以上的架構圖我們看到,第一個是我們談論的 Granite Ridge SOC,它有 8個經典內核和 32 MB L3,該 SOC中最多配備兩個 CCD,因此總共有 16個核心、32個線程和 64 MB L3,這是一個同質的架構,真正的目的是在每個地方都能保持調度以提供效能和意識
簡單的說,從電源效率的角度來看,效能可以橫向擴展,再次,雙 CCX具有不對稱的 L3尺寸,這是我們在之前討論時沒有觸及的東西,但這是我們首先要管理不對稱的 L3尺寸。 無論是過去的伺服器、桌面還是客戶端,我們始終採用對稱的 L3大小,這確實提供了我們必須在終端方面進行的一定程度的管理
系統的視圖不是對稱的,是從單一核心的視圖,如果你看一下,不是乘數,一個因子是這個核心所看到的東西,乘以核心數量本質上就是系統視圖。 非對稱 L3面臨著第一年的挑戰,這可能是第一個 SOC,我們為核心複合體提供了兩個獨立的 L3級別,並非常有效地進行管理。 他們的存在是有原因的,您有更大的 L3來支援效能分數
對於這種反應能力,你有一個權衡區域。 功率是關鍵,因此我們在每個項目上花費的面積都會在學位結束時進行仔細審查,當只有較小的核心複合體被點亮來執行我們在筆記型電腦中常見的那些低利用率的高駐留任務時,擁有較小的現金再次可以為您帶來效率
Zen5核心複合體具有多種風格,包括具有 16核心和 64 MB L3的 Granite Ridge SOC,針對其系統的電源效率,特別是在性能橫向擴展中使用不對稱的 L3大小
AMD的緊湊型 Zen 5c核心與 Intel的 E Core本質上不同,但目的與 Intel的 E Core一樣,AMD的 Zen 5c核心的設計目的是比「標準」性能核心佔用更少的處理器晶片空間,同時為要求不高的任務提供足夠的性能,從而節省功耗並提供比以前更高的每平方毫米計算馬力,但相似之處僅止於此,與 Intel不同的是,AMD採用相同的微架構,並透過較小的核心支援相同的功能
在 Zen 5中,AMD還設計了較小的緊湊型 Zen 5c核心,以提供與較大核心幾乎相同的性能,從而防止更快的 Zen 5核心在線程工作負載期間等待緊湊型核心 Intel預計 AMD的緊湊型 Zen 5c核心最終會出現在桌面處理器上,並使用線程放置技術將某些工作負載分配給較小的核心

AMD成功的讓 AVX-512在 Zen 5以正常頻率運作,成功秘訣的根本在於嘗試將其引入與機器的其他部分更加平衡的位置,因此您不必將其視為一次性的,現在它顯然可以消耗更多電量,當然 AVX-256也可以,但最好是事物共同成長。如果您想像我們嘗試將 AVX-512放在 Zen 2上,那麼我們當時剛從 AVX-128發展到 AVX-256,我只是讓他 balance;這就是 Zen,而且它是如此的 balance
總結
AMD Zen 5再次出擊,另一個按節奏的重大效能提升
AVX512具有 512位元 FP資料路徑,可實現吞吐量和 Al提升
高效能及可設定的解決方案可擴充
變體:巔峰性能(“Zen 5”和 “Zen 5c”)
可設定的 FP和快取層次結構
跨產品線的多個流程 “Strix Point”、“Granite Ridge” 帶來卓越效能和遊戲領先地位繼續支援 AM5基礎設施,透過提高整個晶片的運算能力和效率,Strix Point提供了不折不扣的 AI PC解決方案
• FP基礎設施的持續支持
• AMD繼續保持性能和效率之領先地位

有「Father of Zen」之稱的 Mike Clark ( AMD's Corporate Fellow Silicon Design Engineer) 和 Mahesh Subramony (Senior Fellow Design Engineer)於近日對 AMD Zen 5架構之 AVX512、Zen 5c做了更深入的解析
⇧AMD's Corporate Fellow Silicon Design Engineer Mike Clark (the Father of Zen)
Mike Clark提到,AMD的 Zen 5和緊湊型 Zen 5c核心旨在實現高性能和能源效率,包括設計目標
效能
• 再次實現 1T與 2T效能的重大提升
• 未來運算的新基礎
• 512位元資料路徑上的 AVX512可提高吞吐量和 AI提升
平台支援
• 提供「Zen 5」和「Zen 5c」(緊湊型)核心變體
• 支援可設定的 FP512/FP256資料路徑
• 支援擴展和能源效率
• 支援 4nm和 3nm
• 增強的 ISA功能
AMD的 Zen 5架構透過 512位元路徑、AVX 512負載和雙倍 L2到 L1頻寬提升運算能力,支援每個核心兩個執行緒,新一代分支預測器、雙埠 iCache、6k指令、雙埠資料快取、12路關聯性、每週期 8次操作、每週期 6次浮點操作、FADD減少到 2個週期
AMD的 Zen 5架構將跨越 4nm和 3nm製程節點,為下一代 AMD整個 CPU產品堆疊提供動力,涵蓋從桌上型電腦和行動 PC到資料中心的 EPYC處理器,設計一個有凝聚力的底層架構來滿足所有這些市場的需求是一項令人難以置信的工程壯舉
Mike提到 AMD並將於本月底推出 4nm Zen 5晶片處理器,但尚未公佈 3nm變體的時間表,Mike進一步闡述了同時為 4nm和 3nm製程設計 Zen 5的挑戰,Mike稱這兩個版本基本上是「相互疊加」的
Mike說 AMD使用其緊湊型 Zen 5c核心(與 Intel的 E Core類似的專為後台任務設計的較小核心)來降低筆記型電腦處理器的成本並提高效能,然而與競爭對手不同的是,AMD尚未將這些核心引入其桌面產品線,緊湊型 Zen 5c核心標誌著 AMD緊湊型核心的第二次迭代,但目前尚未計劃用於 Ryzen 9000系列,不過未來的 Ryzen桌上型處理器則將採用緊湊型 Zen 5c核心,並且拓展至獨特實現的技術
Zen 5之加載儲存單元將其從 3D增加到 48K,採用 12路設計,同時保持較低的延遲
AMD並已將其 TLBs(高速緩存)的大小增加到 96個條目,並進行了其他改進以優化效能
眾所皆知,Intel放棄了對高性能 AVX-512指令注入硬體加速支持,但 AMD的 Zen 5則標誌著 Ryzen系列全面支援 AVX-512的加速,與 Intel不同的是,Intel在處理器運行 AVX-512工作負載時必須降低頻率速度,而 AMD的 AVX-512指令集則將以相同的頻率速度來運作標準整數運算, Mike也詳細介紹了該公司如何實現這一壯舉,並表示其 Zen 5c核心也可以運行完整的 AVX-512,AMD並提高了分支預測能力,增加了 L1的規模,並增強了階段能力
AMD的新處理器具有更有效率的調度接口,可以前饋更多指令,Op-cache現在儲存的是指令而不是操作,並且可以將兩個指令融合為一個,Zen 5架構透過並行解碼兩個管道、在 T模式下為每個執行緒專用一個管道以及使用寬調度來退出 8個指令來提高效能,AMD進行了一些更改,以提高處理器指令分配的效率和對稱性,從而實現更精簡的調度
透過優化執行管道以及使用 FMA、F-moles和 FP進行整數存儲,將浮點性能提高了 33%,同時增加了調度程序以適應資料成長,將實體暫存器檔案增加了一倍
AMD的目標是透過將其分成更小的區塊、自然地降低功耗以及對所有核心使用相同的 IPC和 ISO來優化其設計,他們還可以安排節能核心進行多執行緒工作,或使用經典複合體進行低功耗工作,強大的 IPC可以在調度錯誤時快速反應並修正
Zen 5引入了新指令 ISA,包括 AVX512,用於繞過快取的直接儲存以支援 VP2相交,從而在 VE編碼中啟用 VNNI
AMD的目標是在未來工作負載的平衡基礎上提高運算能力,而 Zen 5做到了這點,Zen 5核心的單核心效能比 Zen 4核心快了 40%,Zen 5架構與 Zen 4架構相比,IPC會有 15%的提升,基於 Zen 5架構的處理器在頻率上還會有拉升,Zen 5架構改進的部分還包括:
- 提高性能和能源效率
- 重新設計的管線前端和寬度問題
- 整合人工智慧並優化機器學習
我們將 L2關聯性從 8路增加了一倍到 16路,我們將 L2到 L1 的頻寬從 32位元組增加了一倍到 64 位元組,L3 一點延遲,但我們現在實際上可以在 L3 中實現 320次飛行中的失誤,並且具有 Zen 4之前的所有優點,其中 L2快速且私密
L3和 L2在複合體內共用,因此我們獲得了 L3和 L2的全部容量,我認為我們將這些核心運行到客戶端空間的 SOC中,包括行動和桌面部分,這就是我們在這裡所做的事情,但正如我們所說,Zen繼續發展 Zen5核心複合體,最後一級會有 N個核心
Strix Point SOC架構圖解析
Mahesh Subramony說 : 展望未來,正如 Mark所指出的,將會有一部以 Zen課程為基礎的史詩,並且將會有更小、更大的 CCX,它們將在從客戶端到嵌入到中間的所有內容中發揮作用。因此,我們可以使用同質、異質複合體來申請 HSOC,並且您將看到許多基於 Zen 5的產品
多年來我們的堆疊中。因此,快速瀏覽一下您所看到的,Zen 5兩個核心複合體,一個在 B,兩個核心,16個在 B,8個在 B,有兩個核心複合體,在數據中,這六個 CX中的每一個,每個週期 32字節,讀取和寫入,進入無限結構,進入 GPU,你有一個 HWGPR16、CU、RDNA 3.5引擎,這就是問題類型,糾正一下,那就是 RDNA 3.5,每個週期透過四個 32個位元組、四個圖形連接到資料結構,工作負載對頻寬更加敏感,整個,允許它利用大數據路徑對我們來說至關重要
第三個是計算,NPU具有 XDNA 2推理引擎的 4×8陣列,並且還透過每週期 32位元組的資料連接埠連接到 infrasy結構。
,除此之外,我們還有一些加速器和微控制器,我們早些時候在 APU方面談到了這一點,另一方面,進一步改進我們所有的加速器和微控制器。視訊編碼解碼、音訊編碼處理都是為了效率。再次顯示控制器以實現同時顯示。而且你有系統管理,一堆微控制器管理電源、安全性、可管理性,以及我們需要管理的某些 I/O的單獨控制器,因此,需要一些全面的微控制器來幫助協調系統內的系統管理功能,然後,當我們關注 I/O時,再次看到 128位元 LP5/D5組合,LP上每秒 7,500兆傳輸,DDR5上每秒 5,600兆傳輸,PCIe Gen4的 16通道。我知道有一次會議提出了將車道從 20條減少到 16條的問題
在功率方面,我們注意到從系統的角度來看,額外的完整通道被用於輔助存儲,你知道它沒有太多的連接,因此,我們從二級儲存中去除了我們所擁有的一點額外的靈活性,我們將再次重新審視這一點。但在本例中,我們將這些通道從第四代 20通道的熱點減少到 16通道
USB 3.2 C型、兩個 USB 3.2 A型端口和三個額外的 USB 2端口,用於我們認為該 SOC所需的所有連接,當然,其他 GPIO、A2C是由 eSpy開發的
RDNA 3.5架構圖解析
再次快速深入了解 RDNA 3.5的改進內容, RDNA 3.5它不是架構改進的世代跳躍。我想確保這一點很清楚,正如 Mike所提到的,根據我們與移動朋友的合作關係,我們可以從這個引擎中獲得功率效率的擠壓。因此,將一些效率帶入引擎是主要的驅動力,但我們沒有安裝更大的發動機,所以驅動這些效率使我們能夠安裝更大的發動機,所以它是一個 AWGP發動機,老實說,這是一個更大的引擎,這就是我們在這裡獲得大部分性能提升的方式。但同樣,從每瓦功率性能和每比特性能的角度來看,我們所取得的效率使我們能夠將該引擎壓縮到我們擁有的較小的 TDP預算中。因此,從紋理子系統的角度快速接觸一些子系統,以及我們的雙倍速率上一些最常見的紋理採樣操作的範例子集
現在可以以某種特定的通用格式並行處理一個 PM2D紋理的兩個四邊形樣本。所以這對於一些常見的遊戲紋理操作來說是一個顯著的加速。點採樣加速,因此硬體可以偵測到平點採樣的使用,並將這些採樣操作引導到更快、功耗更低的處理部分,從而再次節省功耗。我想我們確實注意到這裡是一個減壓軸,因此,新的硬體允許多個請求 ALU通道透過解壓縮器共享相同紋理的輸出。這允許 GPU透過關閉一些未使用的解壓縮器來節省電力,文本子系統中的小技巧使我們能夠從系統中獲得這種效率。從著色器子系統的角度來看,同樣是兩個 x插值和比較率。其中,你知道,插值的向量化和現在比較是雙重評級的,這兩種操作在圖形區域中都很常見,標量 ALU中支援浮點,因此這提高了任何需要浮點的波統一計算的效率,在某些圖形技術中開始變得更加常見。所以我們加入了這一點,Mike談到了這個新的 SAALU 指令,它告訴著色器處理器它可以跳過一次性 VGPR,立即使用或使用一次然後丟棄的結果。因此,RDNA 3.5現在允許硬體檢測到這一點並將結果直接轉發到後續指令,從而跳過該指令。所以所有這些改變都可以提高效能和效率,快速進入柵格子系統。是的,所以 RDNA 3處理幾何圖形和批次以最大限度地減少外部內存,3.5向前邁出了一步,它增加了將這些批次分成更小的子批次的支援。因此,這使得硬體總體上更加高效,特別是在需要批量進給處理時。這變得非常有幫助。它還添加了可編程的 bin順序。因此,這增加了新批次的第一個 bin是先前批次的最後一個 bin的可能性,因此本質上所有這些都驅動時間局部性減少外部記憶體存取量,對嗎?正如 Mike所提到的,時間和空間局部性。同樣,每比特的性能,推動了更高能效的底線
任何最終內存子系統的改進,LP-DDR5的運作方式與 G略有不同,因此請注意這一點並獲得更多開啟頁面的點擊率,從而提高效率並改善壓縮。您知道,在圖形渲染期間,通常需要編寫顏色渲染目標,然後將其附加到幀的不同部分的讀取/寫入,所以 DNA 3.5提高了能力更頻繁地進行正確操作,以便稍後可以對其進行解壓縮,從而提高整體記憶體壓縮,然後將這種效率提高到系統
XDNA 2架構圖解析
我將詳細介紹 XDNA 2,但只要抓住這裡的關鍵點,就可以廣泛支援 AI模型,我們談到的血統是能夠為多代設計這些引擎,並將這種經驗帶到這裡。它是一台可配置的機器。它具有能夠的靈活性,它適應未來不斷發展的模型,可以利用並發性,從峰值效能的角度來看,它有 15個大的下降,可以阻止流量,我們談到的 FB16,8位元的吞吐量,但精度為 16,同樣,資料類型非常重要並推動這一點。我認為您會看到我們的許多競爭對手也將開始朝這個方向前進,試圖在您獲得這種效率的資料類型中找到更高的效率,對右翼群體產生良好影響,所以我認為我們正在破土動工,並讓人們更多地了解其準確性,而不僅僅是關心峰頂,我認為隨著這個領域的不斷發展,我們將對此有更多的了解
一代又一代,我認為這只是兩個 X以上的並發空間流,更多的內存,腳堤上的容量,那些引擎,同樣在每個圖塊的基礎上,我們也將 MAC增加了一倍,您也可以透過這種方式擁有引擎,以及 50%的權重稀疏性和增強的對非線性函數的支持。所以這一切都只是這些機器的傳統中汲取的設計可以提高能源效率,擁有像這樣的大型引擎並且無法提取電源效率,或者如果它可能是一種犯罪,當我們達到能夠限制效果和應用程式在列或列對上運行的程度時,能夠為門供電這些附加列完全完整,並且具有僅針對該用例需要點亮的資料路徑,我認為它會取得成果,現在,我們將所有內容都放在一個通用引擎上,將這種計算視為具有大記憶體的單一計算,儘管這種設計可以透過我們的自適應網格互連演變為看起來像這樣,我們擁有最後一級記憶體的方式以及我們如何管理它,我們可以讓它看起來像那個大型引擎。我認為我們已經承擔了增加這種靈活性的一些負擔,您相信,隨著軟體發展到始終在後台運行並且只需要該引擎的一個子集來滿足這些要求,它將取得成果
Granite Ridge SOC架構圖解析
我們推出的下一個 SOC是 Granite Ridge SOC,最多兩個 8個核心 16個線程複合體,每個核心 1MB和 2個 CCD,每個 CCD 32MB L3。正如 Mike 所提到的,FB的 5核位資料路徑,但同樣從我們的製程節點角度以及高頻設計的角度來看,該核心都經過了最佳化。每個連接埠的資料路徑為每個週期 32位元組,因此每個 CCD都有進入 I/O晶片的資料路徑。 GPU維持不變,如果你願意的話,確實需要配置來照亮這個地方,而且,由於引擎精簡,它的資料也更小,每個週期只有兩個 32位元組連接埠進入記憶體。它確實具有視訊編碼解碼、音訊處理器和顯示控制器以及系統管理和安全性,就像上一代一樣。在 I/O方面,同樣是 128位元 DDR5、28條 PCIe Gen5通道,以及 5個 USB端口,其中三種類型為 C型,然後再次連接 USB 2 連接埠,可以支援同步顯示流,並擁有 I2C、spy 和 GPIO所需的所有 I/O。因此,從 I/O晶片的角度來看,我們完全使用了上一代的產品,使我們能夠適應 AM5,CCB的尺寸確實增加了,以提供 IPC和性能改進,Mike談到了這一點,但是然後封裝前端能夠將更大的 CCD安裝到相同的 AM5基礎架構中,以便使用者可以從下一代的平台重用中受益,這也是我們未來的關鍵設計目標
從以上的架構圖我們看到,第一個是我們談論的 Granite Ridge SOC,它有 8個經典內核和 32 MB L3,該 SOC中最多配備兩個 CCD,因此總共有 16個核心、32個線程和 64 MB L3,這是一個同質的架構,真正的目的是在每個地方都能保持調度以提供效能和意識
簡單的說,從電源效率的角度來看,效能可以橫向擴展,再次,雙 CCX具有不對稱的 L3尺寸,這是我們在之前討論時沒有觸及的東西,但這是我們首先要管理不對稱的 L3尺寸。 無論是過去的伺服器、桌面還是客戶端,我們始終採用對稱的 L3大小,這確實提供了我們必須在終端方面進行的一定程度的管理
系統的視圖不是對稱的,是從單一核心的視圖,如果你看一下,不是乘數,一個因子是這個核心所看到的東西,乘以核心數量本質上就是系統視圖。 非對稱 L3面臨著第一年的挑戰,這可能是第一個 SOC,我們為核心複合體提供了兩個獨立的 L3級別,並非常有效地進行管理。 他們的存在是有原因的,您有更大的 L3來支援效能分數
對於這種反應能力,你有一個權衡區域。 功率是關鍵,因此我們在每個項目上花費的面積都會在學位結束時進行仔細審查,當只有較小的核心複合體被點亮來執行我們在筆記型電腦中常見的那些低利用率的高駐留任務時,擁有較小的現金再次可以為您帶來效率
Zen5核心複合體具有多種風格,包括具有 16核心和 64 MB L3的 Granite Ridge SOC,針對其系統的電源效率,特別是在性能橫向擴展中使用不對稱的 L3大小
AMD的緊湊型 Zen 5c核心與 Intel的 E Core本質上不同,但目的與 Intel的 E Core一樣,AMD的 Zen 5c核心的設計目的是比「標準」性能核心佔用更少的處理器晶片空間,同時為要求不高的任務提供足夠的性能,從而節省功耗並提供比以前更高的每平方毫米計算馬力,但相似之處僅止於此,與 Intel不同的是,AMD採用相同的微架構,並透過較小的核心支援相同的功能
在 Zen 5中,AMD還設計了較小的緊湊型 Zen 5c核心,以提供與較大核心幾乎相同的性能,從而防止更快的 Zen 5核心在線程工作負載期間等待緊湊型核心 Intel預計 AMD的緊湊型 Zen 5c核心最終會出現在桌面處理器上,並使用線程放置技術將某些工作負載分配給較小的核心
AMD成功的讓 AVX-512在 Zen 5以正常頻率運作,成功秘訣的根本在於嘗試將其引入與機器的其他部分更加平衡的位置,因此您不必將其視為一次性的,現在它顯然可以消耗更多電量,當然 AVX-256也可以,但最好是事物共同成長。如果您想像我們嘗試將 AVX-512放在 Zen 2上,那麼我們當時剛從 AVX-128發展到 AVX-256,我只是讓他 balance;這就是 Zen,而且它是如此的 balance
總結
AMD Zen 5再次出擊,另一個按節奏的重大效能提升
AVX512具有 512位元 FP資料路徑,可實現吞吐量和 Al提升
高效能及可設定的解決方案可擴充
變體:巔峰性能(“Zen 5”和 “Zen 5c”)
可設定的 FP和快取層次結構
跨產品線的多個流程 “Strix Point”、“Granite Ridge” 帶來卓越效能和遊戲領先地位繼續支援 AM5基礎設施,透過提高整個晶片的運算能力和效率,Strix Point提供了不折不扣的 AI PC解決方案
• FP基礎設施的持續支持
• AMD繼續保持性能和效率之領先地位





