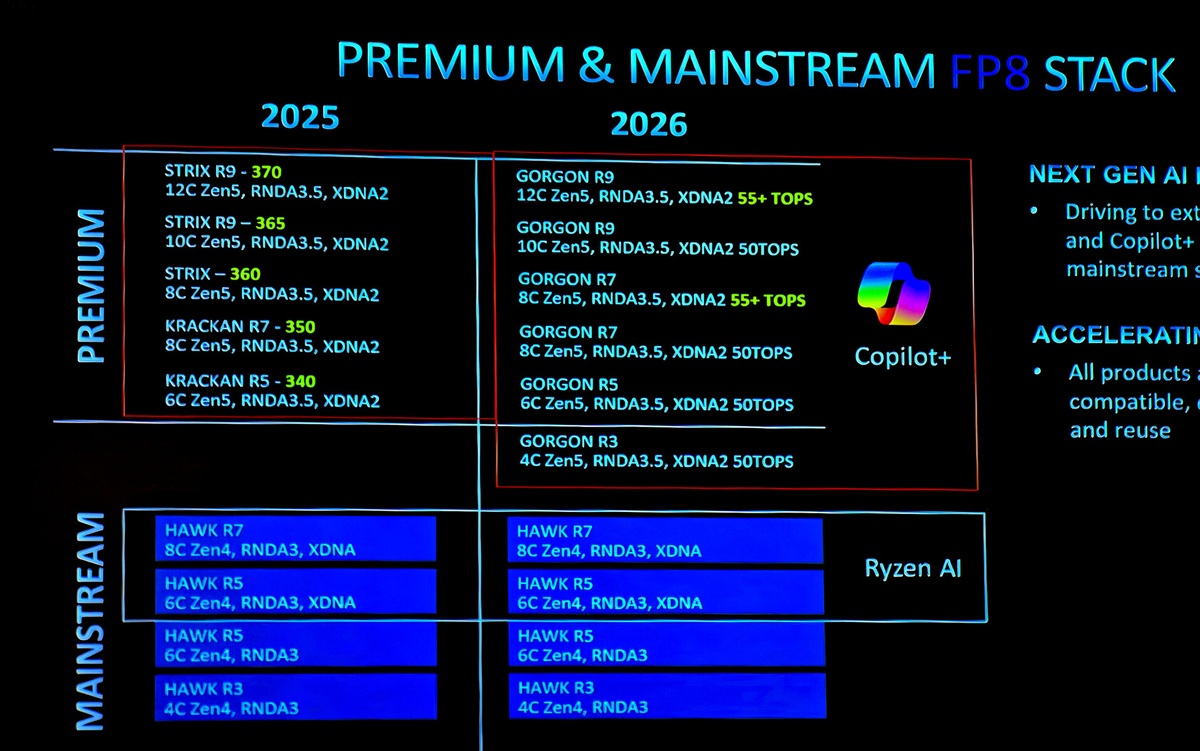
語言模型自GPT-2以來已取得大幅進步,使用者現在可以藉由LM Studio等消費級應用程式快速且輕鬆地部署高度複雜的大型語言模型(LLM)。透過與AMD合作,這些工具讓每個人都能使用人工智慧(AI),且無需任何編碼或技術知識。

llama.cpp和LM Studio概述
LM Studio基於llama.cpp項目,是一個廣受歡迎的框架,用於快速且輕鬆地部署語言模型。LM Studio沒有相依性(dependencies),僅使用CPU即可進行加速,亦支援GPU加速功能。LM Studio使用AVX2指令集來加速基於x86 CPU的現代LLM。
效能對比:吞吐量和延遲
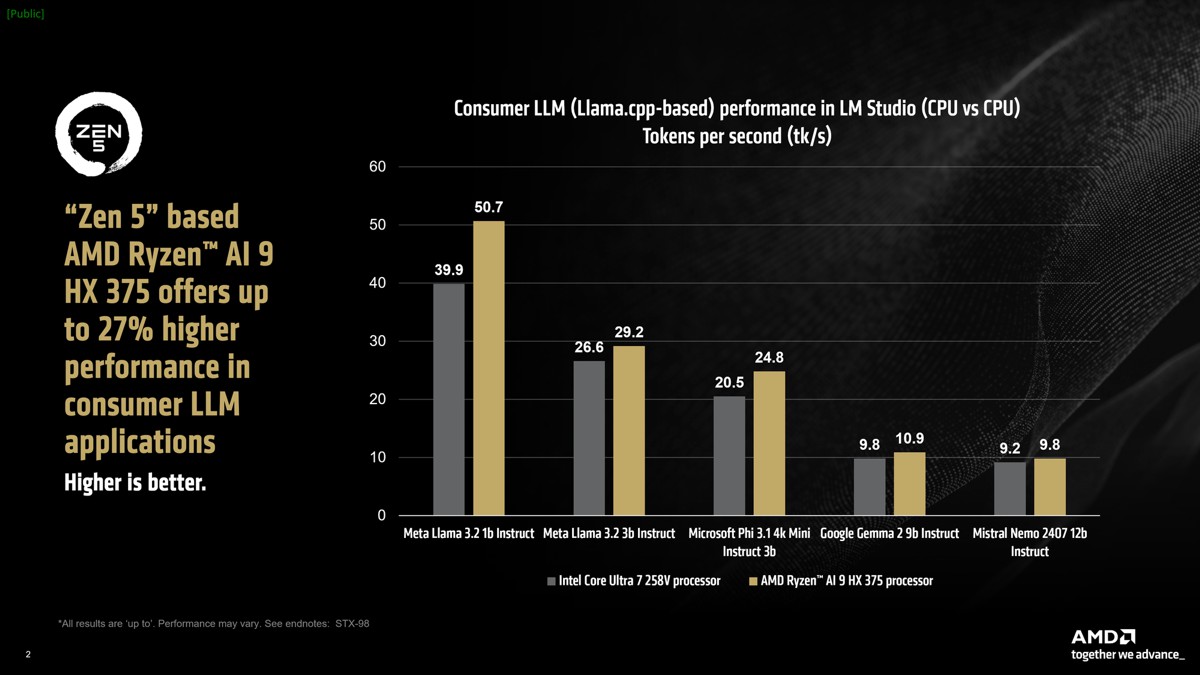
AMD Ryzen™ AI為這些最先進的工作負載進行加速,在x86筆電上運行LM Studio等基於llama.cpp的應用程式提供領先業界的效能註1。值得注意的是,LLM通常對記憶體速度非常敏感。
在我們的對比測試中,Intel筆電的RAM實際上速度較快,達到8533 MT/s,而AMD筆電的RAM為7500 MT/s。儘管如此,AMD Ryzen™ AI 9 HX 375處理器的每秒token生成速度(tokens per second)比競爭對手快出高達27%。參考資料顯示tokens per second (tk/s)是測量LLM輸出token速度的指標,大約對應於每秒在螢幕上顯示的字數。
AMD Ryzen™ AI 9 HX 375處理器在Meta Llama 3.2 1b Instruct(4-bit量化)中可實現每秒高達50.7個token的效能。
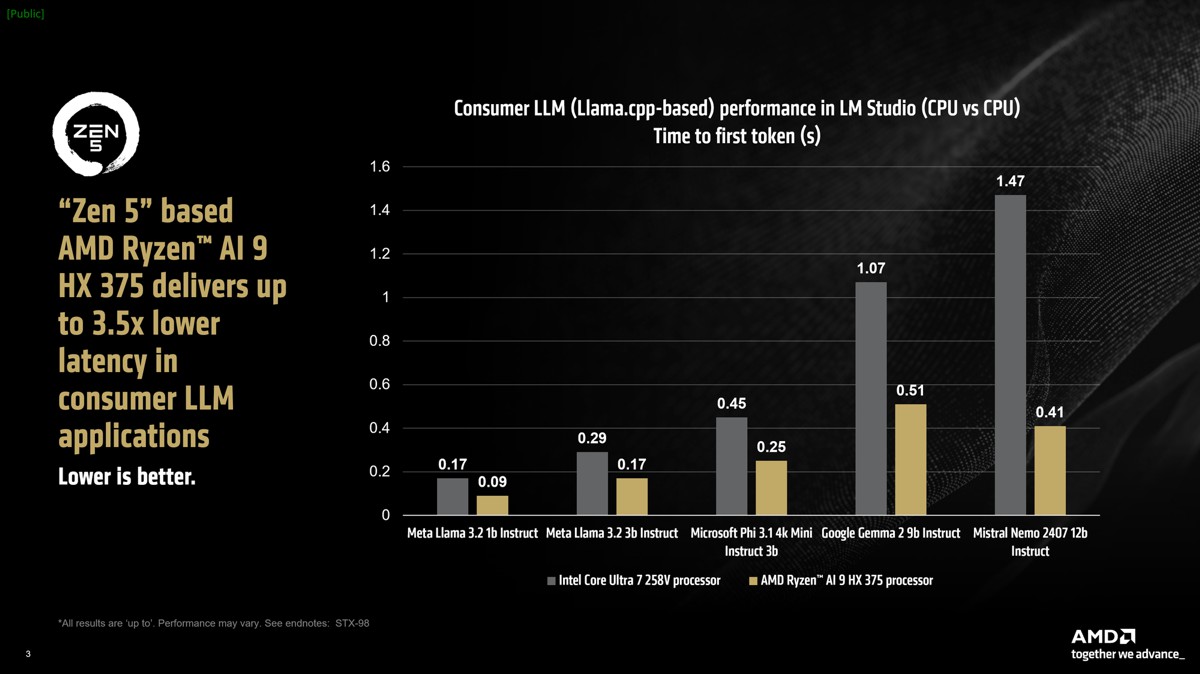
對大型語言模型進行基準測試的另一個指標是「輸出首個token的時間(time to first token)」,測量從提交提示(prompt)至模型開始生成token之間的延遲時間。在較大模型中,基於AMD “Zen 5”架構的Ryzen™ AI HX 375處理器的速度相較競爭對手的同級處理器快出高達3.5倍註1。
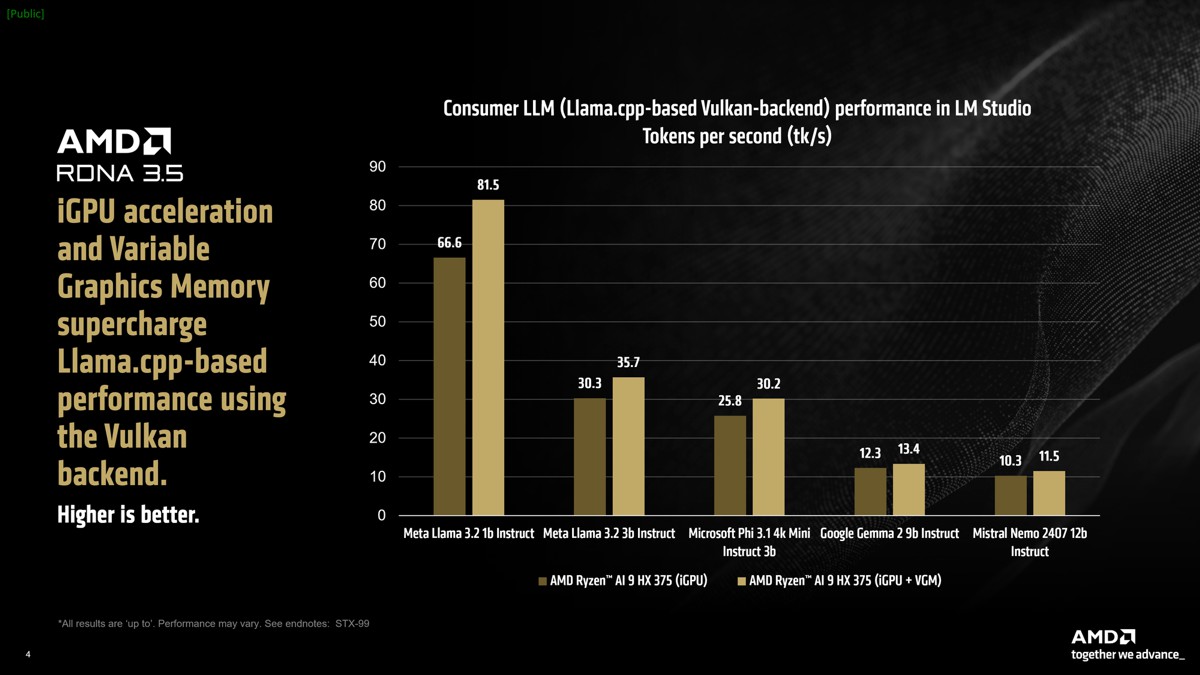
在Windows中使用可變顯示記憶體(VGM)來提高模型吞吐量
AMD Ryzen™ AI CPU中的三個加速器各自擁有特定的工作負載專業化和擅長的情境。基於AMD XDNA™ 2架構的NPU在執行Copilot+工作負載時為持續的AI功能提供卓越的功耗效率,CPU為工具和框架提供廣泛的覆蓋範圍和相容性,而內顯(iGPU)通常根據需求處理AI任務。
LM Studio提供llama.cpp的連接埠(port),可使用與供應商無關(vendor-agnostic)的Vulkan API來加速框架。此加速通常取決於硬體功能和Vulkan API的驅動程式最佳化的組合。與僅使用CPU模式相比,在LM Studio中開啟GPU offload後Meta Llama 3.2 1b Instruct的效能平均提升31%。Mistral Nemo 2407 12b Instruct等較大模型在token生成階段由於受到頻寬限制,平均效能提升5.1%。
我們觀察到在LM Studio中使用基於Vulkan的llama.cpp版本並開啟GPU offload時,與僅使用CPU的模式相比,競爭對手處理器除了其中一個模型外,其餘測試模型的平均效能皆明顯較低。因此,為了保持對比測試的公平性,我們沒有將Intel Core Ultra 7 258v在LM Studio中使用基於Vulkan之Llama.cpp的GPU-offload效能納入比較。
AMD Ryzen™ AI 300系列處理器還包括一項名為可變顯示記憶體(VGM)的功能。通常程式會利用為iGPU分配的512 MB專用記憶區塊,以及位於系統RAM「共享」部分的第二個記憶區塊。VGM讓使用者將512 MB的「專用」分配擴展到高達75%的可用系統RAM容量。這種連續記憶體的分配顯著提升了對記憶體敏感應用程式的吞吐量。
在開啟VGM(16GB)後,Meta Llama 3.2 1b Instruct的效能平均提升22%,與使用iGPU加速並結合VGM的CPU模式相比,平均速度共提升60%。Mistral Nemo 2407 12b Instruct等更大模型相較僅使用CPU的模式,帶來高達17%的效能提升。
同步比較:Mistral 7b Instruct 0.3
儘管競爭對手的筆電在LM Studio中使用基於Vulkan的Llama.cpp版本沒有提供加速,我們仍使用Intel AI Playground應用程式(基於IPEX-LLM和LangChain)來比較iGPU效能,力求在最佳的消費級LLM體驗之間進行公平的比較。
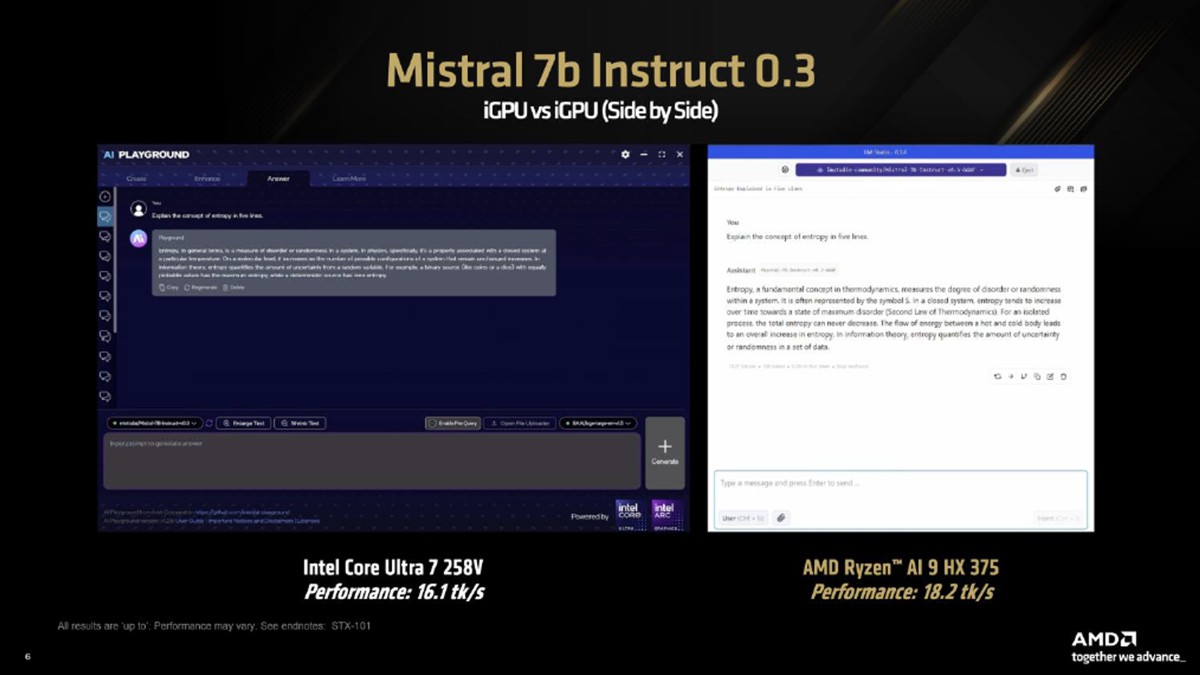
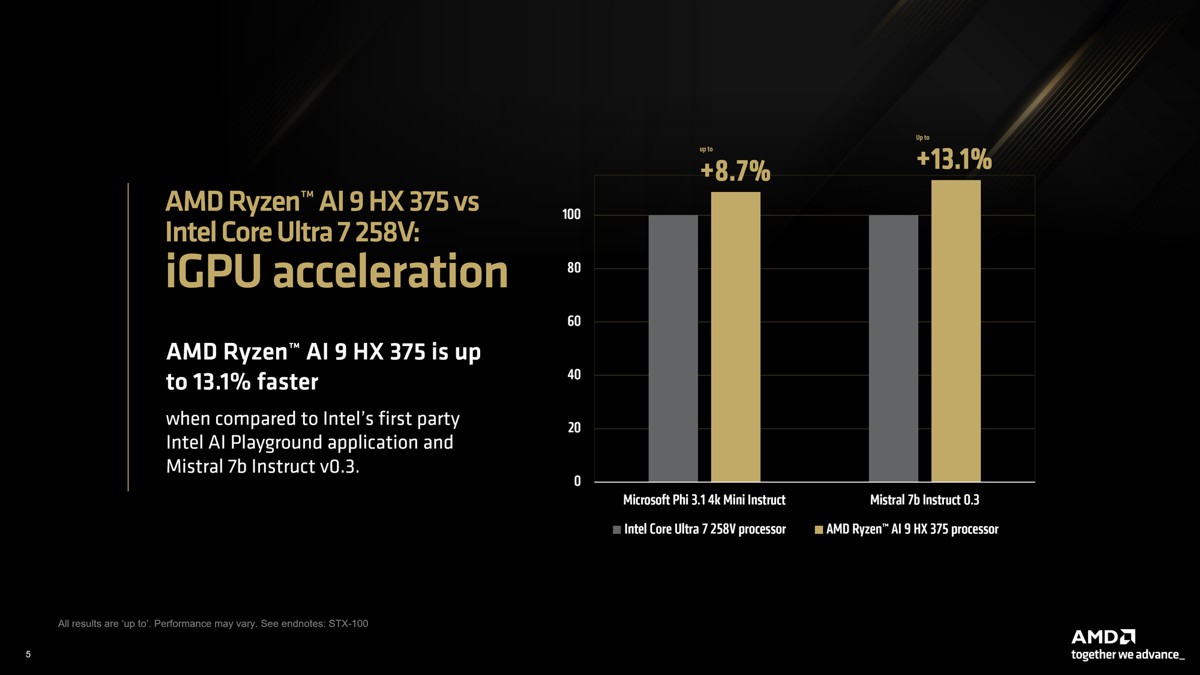
我們使用Intel AI Playground提供的模型,即Mistral 7b Instruct v0.3和Microsoft Phi 3.1 Mini Instruct。在LM Studio中使用可比較的量化後,我們發現AMD Ryzen™ AI 9 HX 375在Phi 3.1的速度比競爭對手快8.7%,在Mistral 7b Instruct 0.3的速度則快13%。
AMD致力於推進AI技術的發展,讓每個人皆能使用AI。若最新的AI進展被設置在高門檻的技術或編碼技能,這目標將無法實現,這就是為何LM Studio等應用如此重要。除了能夠快速且輕鬆地在本地部署LLM外,這些應用程式讓使用者在llama.cpp項目支援該架構的情況下,第一時間體驗最先進的模型。
AMD Ryzen™ AI加速器提供卓越效能,開啟VGM等功能可為AI使用案例提供更好的效能。所有因素結合起來後,為x86筆電上的語言模型提供了令人驚豔的使用者體驗。
欲親自體驗LM Studio,請參閱此連結。
註1:在此次比較中,我們選擇採購當時在北美市場上最好的14吋筆電。
註2:STX-98:截至2024年10月由AMD進行的測試。對於樣本提示「用五行解釋熵的概念」進行3次執行的平均效能。所有測試均在LM Studio 0.3.4上進行。測試的模型包括:Meta Llama 3.2 1b Instruct、Meta Llama 3.2 3b Instruct、Microsoft Phi 3.1 4k Mini Instruct、Google Gemma 2 9b Instruct、Mistral Nemo 2407 13b Instruct。(所有模型均為Q4 K M量化)。Intel的特定配置:8個CPU執行緒。AMD的特定配置:12個執行緒。(Llama.cpp建議將執行緒設置為物理核心的數量)。搭載AMD Ryzen AI 9 HX 375的HP OmniBook Ultra筆電,32GB 7500 MT/s RAM,開啟VBS,Windows 11 Pro 24H2。搭載Intel Core Ultra 7 258V的ASUS Zenbook S14 UX5406SA 14吋筆電腦,32GB 8533 MT/s RAM,啟用VBS,Windows 11 Pro 24H2。效能可能會改變。
註3:STX-99:截至2024年10月由AMD進行的測試。對於樣本提示「用五行解釋熵的概念」進行3次執行的平均效能。所有測試均在LM Studio 0.3.4上進行。測試的模型包括:Meta Llama 3.2 1b Instruct、Meta Llama 3.2 3b Instruct、Microsoft Phi 3.1 4k Mini Instruct、Google Gemma 2 9b Instruct、Mistral Nemo 2407 13b Instruct。(所有模型均為Q4 K M量化)。12個CPU執行緒。(Llama.cpp建議將執行緒設置為物理核心的數量)。GPU offload = MAX。VGM在VGM執行期間設置為16GB。搭載AMD Ryzen AI 9 HX 375的HP OmniBook Ultra筆電,32GB 7500 MT/s RAM,啟用VBS,Windows 11 Pro 24H2。效能可能會改變。
註4:STX-100:截至2024年10月由AMD進行的測試。對於樣本提示「從10公尺高處掉落的球需要多久時間才能落地?」,「用五行解釋熵的概念」。所有測試均在AMD筆電上使用LM Studio 0.3.4進行。所有測試均在Intel筆電上使用Intel AI Playground 1.21b進行。測試的模型包括:Mistral 7b Instruct v0.3 Q4 K M、Mistral 7b Instruct v0.3 sym_int4、Microsoft Phi 3.1 4k Mini Instruct Q4 K M、Microsoft Phi 3.1 4k Mini Instruct sym_int4。AMD的特定配置:12個執行緒。(Llama.cpp建議將執行緒設置為物理核心的數量)。GPU offload = MAX。VGM在VGM 測試期間設置為16GB。搭載AMD Ryzen AI 9 HX 375的HP OmniBook Ultra筆電,32GB 7500 MT/s RAM,開啟VBS,Windows 11 Pro 24H2。搭載Intel Core Ultra 7 258V的ASUS Zenbook S14 UX5406SA 14吋筆電,32GB 8533 MT/s RAM,啟用VBS,Windows 11 Pro 24H2。效能可能會改變。
註5:STX-101:截至2024年10月由AMD進行的測試。對於樣本提示「用五行解釋熵的概念」進行3次執行的平均效能。所有測試均在AMD筆電上使用LM Studio 0.3.4進行。所有測試均在Intel筆電上使用Intel AI Playground 1.21b進行。測試的模型包括:Mistral 7b Instruct v0.3 Q4 K M、Mistral 7b Instruct v0.3 sym_int4。AMD的特定配置:12個執行緒。(Llama.cpp建議將執行緒設置為物理核心的數量)。GPU offload = MAX。VGM在VGM測試期間設置為16GB。搭載AMD Ryzen AI 9 HX 375的HP OmniBook Ultra筆電,32GB 7500 MT/s RAM,開啟VBS,Windows 11 Pro 24H2。搭載Intel Core Ultra 7 258V的ASUS Zenbook S14 UX5406SA 14吋筆電,32GB 8533 MT/s RAM,啟用VBS,Windows 11 Pro 24H2。效能可能會改變。
註6:GD-220c:Ryzen™ AI被定義為專用AI引擎、AMD Radeon™顯示引擎和Ryzen處理器核心的組合,使得AI功能得以實現。需要OEM 和ISV的支援,某些AI功能可能尚未針對Ryzen AI處理器進行最佳化。Ryzen AI與以下產品相容:(a)除了Ryzen 5 7540U、Ryzen 5 8540U、Ryzen 3 7440U和Ryzen 3 8440U處理器以外的所有AMD Ryzen 7040和8040系列處理器;(b)所有AMD Ryzen AI 300系列處理器;(c)除了Ryzen 5 8500G/GE和Ryzen 3 8300G/GE的所有AMD Ryzen 8000G系列桌上型處理器。請在購買前向系統製造商確認功能的可用性。
llama.cpp和LM Studio概述
LM Studio基於llama.cpp項目,是一個廣受歡迎的框架,用於快速且輕鬆地部署語言模型。LM Studio沒有相依性(dependencies),僅使用CPU即可進行加速,亦支援GPU加速功能。LM Studio使用AVX2指令集來加速基於x86 CPU的現代LLM。
效能對比:吞吐量和延遲
AMD Ryzen™ AI為這些最先進的工作負載進行加速,在x86筆電上運行LM Studio等基於llama.cpp的應用程式提供領先業界的效能註1。值得注意的是,LLM通常對記憶體速度非常敏感。
在我們的對比測試中,Intel筆電的RAM實際上速度較快,達到8533 MT/s,而AMD筆電的RAM為7500 MT/s。儘管如此,AMD Ryzen™ AI 9 HX 375處理器的每秒token生成速度(tokens per second)比競爭對手快出高達27%。參考資料顯示tokens per second (tk/s)是測量LLM輸出token速度的指標,大約對應於每秒在螢幕上顯示的字數。
AMD Ryzen™ AI 9 HX 375處理器在Meta Llama 3.2 1b Instruct(4-bit量化)中可實現每秒高達50.7個token的效能。
對大型語言模型進行基準測試的另一個指標是「輸出首個token的時間(time to first token)」,測量從提交提示(prompt)至模型開始生成token之間的延遲時間。在較大模型中,基於AMD “Zen 5”架構的Ryzen™ AI HX 375處理器的速度相較競爭對手的同級處理器快出高達3.5倍註1。
在Windows中使用可變顯示記憶體(VGM)來提高模型吞吐量
AMD Ryzen™ AI CPU中的三個加速器各自擁有特定的工作負載專業化和擅長的情境。基於AMD XDNA™ 2架構的NPU在執行Copilot+工作負載時為持續的AI功能提供卓越的功耗效率,CPU為工具和框架提供廣泛的覆蓋範圍和相容性,而內顯(iGPU)通常根據需求處理AI任務。
LM Studio提供llama.cpp的連接埠(port),可使用與供應商無關(vendor-agnostic)的Vulkan API來加速框架。此加速通常取決於硬體功能和Vulkan API的驅動程式最佳化的組合。與僅使用CPU模式相比,在LM Studio中開啟GPU offload後Meta Llama 3.2 1b Instruct的效能平均提升31%。Mistral Nemo 2407 12b Instruct等較大模型在token生成階段由於受到頻寬限制,平均效能提升5.1%。
我們觀察到在LM Studio中使用基於Vulkan的llama.cpp版本並開啟GPU offload時,與僅使用CPU的模式相比,競爭對手處理器除了其中一個模型外,其餘測試模型的平均效能皆明顯較低。因此,為了保持對比測試的公平性,我們沒有將Intel Core Ultra 7 258v在LM Studio中使用基於Vulkan之Llama.cpp的GPU-offload效能納入比較。
AMD Ryzen™ AI 300系列處理器還包括一項名為可變顯示記憶體(VGM)的功能。通常程式會利用為iGPU分配的512 MB專用記憶區塊,以及位於系統RAM「共享」部分的第二個記憶區塊。VGM讓使用者將512 MB的「專用」分配擴展到高達75%的可用系統RAM容量。這種連續記憶體的分配顯著提升了對記憶體敏感應用程式的吞吐量。
在開啟VGM(16GB)後,Meta Llama 3.2 1b Instruct的效能平均提升22%,與使用iGPU加速並結合VGM的CPU模式相比,平均速度共提升60%。Mistral Nemo 2407 12b Instruct等更大模型相較僅使用CPU的模式,帶來高達17%的效能提升。
同步比較:Mistral 7b Instruct 0.3
儘管競爭對手的筆電在LM Studio中使用基於Vulkan的Llama.cpp版本沒有提供加速,我們仍使用Intel AI Playground應用程式(基於IPEX-LLM和LangChain)來比較iGPU效能,力求在最佳的消費級LLM體驗之間進行公平的比較。
我們使用Intel AI Playground提供的模型,即Mistral 7b Instruct v0.3和Microsoft Phi 3.1 Mini Instruct。在LM Studio中使用可比較的量化後,我們發現AMD Ryzen™ AI 9 HX 375在Phi 3.1的速度比競爭對手快8.7%,在Mistral 7b Instruct 0.3的速度則快13%。
AMD致力於推進AI技術的發展,讓每個人皆能使用AI。若最新的AI進展被設置在高門檻的技術或編碼技能,這目標將無法實現,這就是為何LM Studio等應用如此重要。除了能夠快速且輕鬆地在本地部署LLM外,這些應用程式讓使用者在llama.cpp項目支援該架構的情況下,第一時間體驗最先進的模型。
AMD Ryzen™ AI加速器提供卓越效能,開啟VGM等功能可為AI使用案例提供更好的效能。所有因素結合起來後,為x86筆電上的語言模型提供了令人驚豔的使用者體驗。
欲親自體驗LM Studio,請參閱此連結。
註1:在此次比較中,我們選擇採購當時在北美市場上最好的14吋筆電。
註2:STX-98:截至2024年10月由AMD進行的測試。對於樣本提示「用五行解釋熵的概念」進行3次執行的平均效能。所有測試均在LM Studio 0.3.4上進行。測試的模型包括:Meta Llama 3.2 1b Instruct、Meta Llama 3.2 3b Instruct、Microsoft Phi 3.1 4k Mini Instruct、Google Gemma 2 9b Instruct、Mistral Nemo 2407 13b Instruct。(所有模型均為Q4 K M量化)。Intel的特定配置:8個CPU執行緒。AMD的特定配置:12個執行緒。(Llama.cpp建議將執行緒設置為物理核心的數量)。搭載AMD Ryzen AI 9 HX 375的HP OmniBook Ultra筆電,32GB 7500 MT/s RAM,開啟VBS,Windows 11 Pro 24H2。搭載Intel Core Ultra 7 258V的ASUS Zenbook S14 UX5406SA 14吋筆電腦,32GB 8533 MT/s RAM,啟用VBS,Windows 11 Pro 24H2。效能可能會改變。
註3:STX-99:截至2024年10月由AMD進行的測試。對於樣本提示「用五行解釋熵的概念」進行3次執行的平均效能。所有測試均在LM Studio 0.3.4上進行。測試的模型包括:Meta Llama 3.2 1b Instruct、Meta Llama 3.2 3b Instruct、Microsoft Phi 3.1 4k Mini Instruct、Google Gemma 2 9b Instruct、Mistral Nemo 2407 13b Instruct。(所有模型均為Q4 K M量化)。12個CPU執行緒。(Llama.cpp建議將執行緒設置為物理核心的數量)。GPU offload = MAX。VGM在VGM執行期間設置為16GB。搭載AMD Ryzen AI 9 HX 375的HP OmniBook Ultra筆電,32GB 7500 MT/s RAM,啟用VBS,Windows 11 Pro 24H2。效能可能會改變。
註4:STX-100:截至2024年10月由AMD進行的測試。對於樣本提示「從10公尺高處掉落的球需要多久時間才能落地?」,「用五行解釋熵的概念」。所有測試均在AMD筆電上使用LM Studio 0.3.4進行。所有測試均在Intel筆電上使用Intel AI Playground 1.21b進行。測試的模型包括:Mistral 7b Instruct v0.3 Q4 K M、Mistral 7b Instruct v0.3 sym_int4、Microsoft Phi 3.1 4k Mini Instruct Q4 K M、Microsoft Phi 3.1 4k Mini Instruct sym_int4。AMD的特定配置:12個執行緒。(Llama.cpp建議將執行緒設置為物理核心的數量)。GPU offload = MAX。VGM在VGM 測試期間設置為16GB。搭載AMD Ryzen AI 9 HX 375的HP OmniBook Ultra筆電,32GB 7500 MT/s RAM,開啟VBS,Windows 11 Pro 24H2。搭載Intel Core Ultra 7 258V的ASUS Zenbook S14 UX5406SA 14吋筆電,32GB 8533 MT/s RAM,啟用VBS,Windows 11 Pro 24H2。效能可能會改變。
註5:STX-101:截至2024年10月由AMD進行的測試。對於樣本提示「用五行解釋熵的概念」進行3次執行的平均效能。所有測試均在AMD筆電上使用LM Studio 0.3.4進行。所有測試均在Intel筆電上使用Intel AI Playground 1.21b進行。測試的模型包括:Mistral 7b Instruct v0.3 Q4 K M、Mistral 7b Instruct v0.3 sym_int4。AMD的特定配置:12個執行緒。(Llama.cpp建議將執行緒設置為物理核心的數量)。GPU offload = MAX。VGM在VGM測試期間設置為16GB。搭載AMD Ryzen AI 9 HX 375的HP OmniBook Ultra筆電,32GB 7500 MT/s RAM,開啟VBS,Windows 11 Pro 24H2。搭載Intel Core Ultra 7 258V的ASUS Zenbook S14 UX5406SA 14吋筆電,32GB 8533 MT/s RAM,啟用VBS,Windows 11 Pro 24H2。效能可能會改變。
註6:GD-220c:Ryzen™ AI被定義為專用AI引擎、AMD Radeon™顯示引擎和Ryzen處理器核心的組合,使得AI功能得以實現。需要OEM 和ISV的支援,某些AI功能可能尚未針對Ryzen AI處理器進行最佳化。Ryzen AI與以下產品相容:(a)除了Ryzen 5 7540U、Ryzen 5 8540U、Ryzen 3 7440U和Ryzen 3 8440U處理器以外的所有AMD Ryzen 7040和8040系列處理器;(b)所有AMD Ryzen AI 300系列處理器;(c)除了Ryzen 5 8500G/GE和Ryzen 3 8300G/GE的所有AMD Ryzen 8000G系列桌上型處理器。請在購買前向系統製造商確認功能的可用性。