
雖然 NVIDIA RTX 5090 還未推出,評測解禁時間是在1月23日,販售是1月30日。據傳首發貨不多,甚至部分地區零售商連配貨都沒有,大概又要排隊?不管如何,先來看看這一代 Blackwell 架構帶來的改變與進步。
NVIDIA 稱,目前對於畫面品質的追求已大幅超越了摩爾定律所能夠提供的運算性能,為此加入神經渲染勢在必行,這是電腦圖形學的下一個時代。透過將神經網路整合到渲染過程中,可以在效能、影像品質和互動性方面取得顯著進步,從而提供全新的沉浸式體驗。
在這次的 Blackwell 架構 GPU 上,新一代 Tensor Core 增加了對 FP4 浮點運算精確度的支援。 FP4 是一種較低的量化方法,類似於檔案壓縮,可以減少模型推理過程中資料儲存和運算量大小,提高運算效率,降低流程對記憶體的要求。與大多數預設使用的 FP16 相比,FP4 使用的記憶體不到一半,並使 RTX 50 系列 GPU 的效能相比上一代提升高達2倍。透過利用 NVIDIA Tensor Model Optimizer 提供的高級量化方法,這些增益幾乎不會影響輸出品質。

由於加入了神經渲染,Blackwell 架構 GPU 的 SM 設計也有了變化,與 Tensor Core 的結合變得更加緊密,以便在傳統渲染管線中加入 AI 相關的功能。同時 Shader Core 也不再區分處理 INT32 / FP32 以及僅 FP32 的部分,全部都可以操作 INT32 / FP32。透過傳統 Shader Core 與 Tensor Core 的進一步結合,打造出 RTX 神經著色器( RTX Neural Shaders ),將小型神經網路帶入可程式著色器中,應用範圍包括輻射快取、紋理壓縮、材質、輻射場等。
The RTX Neural Shaders SDK 讓開發者在 RTX AI PC 上訓練他們的遊戲資料和著色器程式碼,並使用 Tensor Cores 在運行時加速其神經表示和模型權重。在訓練過程中,神經遊戲資料與傳統資料的輸出進行比較,並經過多次循環進行最佳化。開發者可以使用 Slang(一種將大型複雜函數拆分為更易處理的小部分的著色語言),以此簡化訓練過程。
這項突破性技術用於三種應用:RTX 神經紋理壓縮、RTX 神經材質和神經網路輻射快取(NRC)。 RTX 神經紋理壓縮使用 AI 在不到一分鐘的時間內壓縮數千種紋理,在相同的視覺品質下可以節省高達7倍的記憶體佔用;RTX 神經材質是使用 AI 壓縮通常保留給離線材質的複雜著色器代碼,而這些材質由多層組成,處理速度可提升5倍;神經網絡輻射快取使用在實時遊戲數據上訓練的神經網絡,能更準確和高效計算遊戲場景中的間接光照,而大幅減少光線追蹤的計算量。
在 RT Core 方面, NVIIDA 主要提升了偵測光線、路徑與三角形相交的效能,現在偵測能夠以簇集方式進行,另外也有三角形簇集解壓縮引擎。其中新增支援 Linear-swept Spheres(LSS),可以減少渲染毛髮所需的幾何圖形數量,並使用球體代替三角形以獲得更準確的毛髮形狀擬合,具有更好的性能和較小的記憶體佔用。
依照 NVIDIA 的說法,相較於首次加入 RT Core 的 Turing 架構,新一代 Blackwell 架構光線、路徑與三角形相交的檢測效率大概提升至原來的8倍,同時相比上一代 Ada Lovelace 架構,能節省約 25% 的記憶體使用率。

考慮到 AI 在遊戲內的應用越來越普遍,如何分配顯示卡內部的多樣化工作成為了新的問題。為此 NVIDIA 在 Blackwell 架構 GPU 上加入了 AI Management Processor ,可以根據不同的實際情況調整資料處理的優先權,以提升反映速度,維持運算效率。對於廣泛應用的 DLSS 來說,可以多幀產生提供一致的畫面產生時間。
Blackwell 架構 GPU 除了整體設計的提升外,很重要一點是加入了對 GDDR7 的支援。與現有 GDDR6 所使用的 NRZ / PAM2 或 GDDT6X 的 PAM4 訊號編碼機制不同,GDDR7 採用的是 PAM3 訊號編碼機制。 NRZ / PAM2 每週期提供1位元的資料傳輸,PAM4 每週期提供2位元的資料傳輸,而 PAM3 每兩個週期的資料傳輸為3位元。整體而言,能夠降低耗電,頻寬也得到了再次提升。
NVIDIA 在電源效率上也下了不少功夫,不僅針對筆記型電腦使用的型號,桌上型電腦使用的 RTX 50 系列顯示卡也因此受惠。 NVIDIA 針對閒置運算單元,在原有基礎上加入了電源軌閘控(Rail Gating),可單獨微調非頻繁操作區域的供電狀況。
NVIDIA 表示,Blackwell 架構的頻率調整速度相比 Ada Lovelace 架構快了上千倍,進入睡眠狀態或喚醒速度也提升了數個量級。這不僅能節省約 50% 的能源消耗,也能更快迎合運算的需求,帶來更好的效能表現。
NVIDIA DLSS 是一套由 RTX Tensor Core 驅動的神經渲染技術,可在提供清晰、高品質影像的同時提升幀率。在新一代 Blackwell 架構 GPU 上,引入了 DLSS 4,具備多幀生成功能,在每個傳統渲染的幀之間產生多達三個額外的幀。

DLSS 4 也引進了自2020年發布 DLSS 2.0 以來對其 AI 模型的最大升級,DLSS 光線重建、DLSS 超解析度和 DLAA 將由 Transformer 模型驅動,這是 Transformer 模型首次在圖形領域的即時應用。 DLSS Transformer 模型透過改進的時間穩定性、減少鬼影以及運動中的更高細節來提升影像品質。
DLSS 3 幀產生的 AI 模型使用遊戲數據,如運動矢向量和深度訊息,以及來自 RTX 40 系列光流加速器的光流場來產生一個額外的幀。這種方式產生多個幀的成本過高,因為每次產生新幀都需要光流加速器和 AI 模型,且效能開銷會限制 GPU,導致輸入幀率降低。
DLSS 4 多幀生成結合了多項 Blackwell 架構的硬體技術和 DLSS 創新,實現了多幀生成。新的幀生成 AI 模型快了40%,使用的記憶體減少了30%,並且只需每渲染一幀運行一次即可產生多個幀。 NVIDIA 透過用一個非常高效的 AI 模型取代硬體光流加速器來加速光流場的生成,顯著降低了生成額外幀的計算成本。
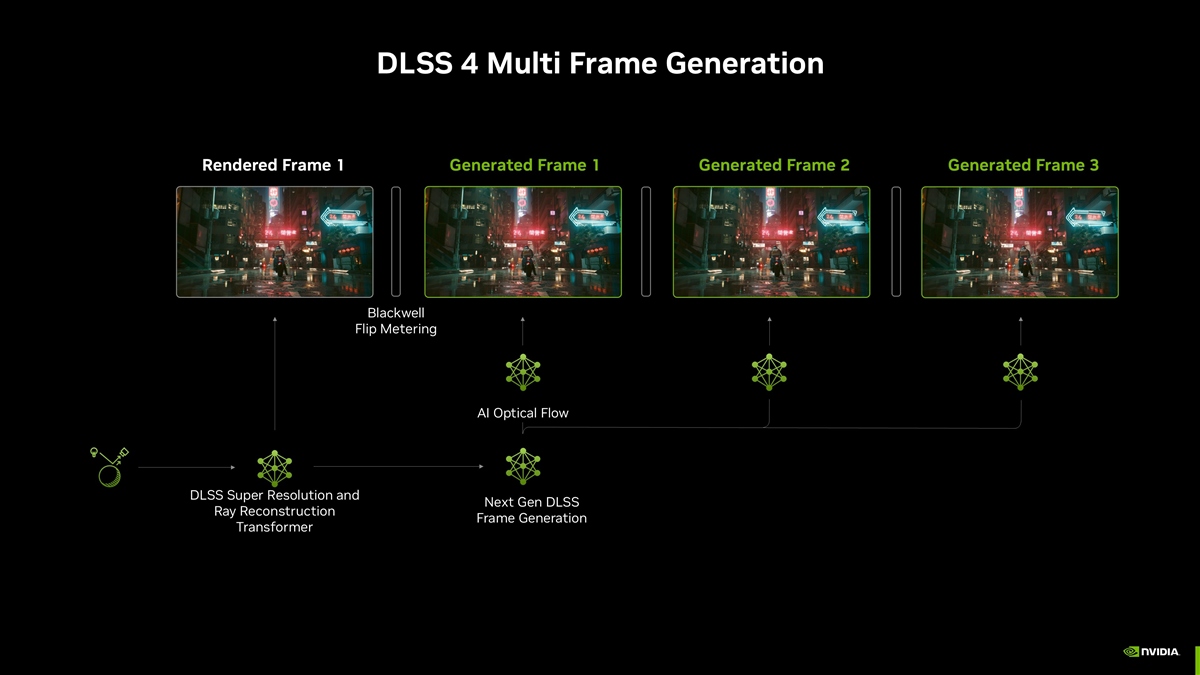
利用 Blackwell 架構 GPU 的第五代 Tensor Core,AI 處理效能提升了最多2.5倍。一旦產生了新的多個幀,它們就會被均勻地安排,以提供流暢的視覺體驗。過去 DLSS 3 幀產生使用基於 GPU 的幀調度,其變異性可能會隨著額外幀的增加而累積,導致每個幀之間的幀調度不一致,影響流暢性。
為了解決產生多個幀的複雜性,Blackwell 架構 GPU 使用 Flip Metering,將幀率邏輯轉移到顯示引擎中,使得 GPU 能夠更精確地管理顯示時間。同時顯示引擎也增強了兩倍的像素處理能力,以支援更高的解析度和更新率,從而實現具有 DLSS 4 的 Flip Metering。
對於遊戲和應用,DLSS 4 結合多幀生成、光線重建和超級解析度技術,將幀率提升至普通渲染的最高8倍,並在從幀生成升級到多幀生成時,進一步提高幀率高達1.7倍,性能提升效果非常明顯。

先前 DLSS 使用卷積神經網路(CNN)透過分析局部上下文並在連續幀中追蹤這些區域的變化來產生新像素,經過六年的持續改進,已經達到了極限。新的 DLSS Transformer 模型使用了視覺 Transformer 變壓器,自注意力機制操作能夠評估整個幀中每個像素的相對重要性,並且跨越多個幀。
DLSS Transformer 模型採用兩倍於 CNN 模型的參數來實現對場景的更深層理解,從而產生提供更高穩定性、減少鬼影、運動細節更多以及場景邊緣更平滑的像素。在密集的光線追蹤內容裡,新的 DLSS Transformer 模型能大幅提升影像質量,在複雜的光照條件下會有更明顯的優勢,穩定性會加強,重影會減少,閃爍現像也會消失。 DLSS 光線重建、DLSS 超解析度和 DLAA 將由 Transformer 模型驅動,這是 Transformer 模型首次在圖形領域的即時應用,它也將進一步提升 RTX 20 / 30 / 40 系列顯示卡的 DLSS 效能體驗。預計在未來數年裡,影像品質會持續提升。
尚未上市的 RTX 50 系列顯示卡已經可以在75款遊戲與應用程式中使用,並利用 DLSS 多幀生成技術實現效能倍增。遊戲的幀生成功能在 RTX 50 / 40 系列上也進行了升級,不僅提升了效能,也減少了記憶體的使用。

在過去四年裡,NVIDIA Reflex 已整合到超過100款遊戲中,可以將 PC 延遲降低 50%。在新一代 Blackwell 架構 GPU 上,帶來了 NVIDIA Reflex 2,結合了 Reflex 低延遲模式和新的 Frame Warp 技術,透過把最新的滑鼠輸入指令及時同步給渲染幀,及時更新渲染的遊戲幀並在渲染幀被發送到顯示器之前獲取最新的滑鼠訊息,透過刷新渲染的遊戲幀以進一步減少延遲,將 PC 延遲進一步降低多達 75%。
在遊戲裡,玩家的每個動作都會經過複雜的計算,然後在螢幕上顯示,其中的每一步都會增加延遲。來自鍵盤和滑鼠的輸入傳輸給遊戲,由 CPU 進行計算其在遊戲中的效果。操作的結果被置於渲染佇列中,佇列傳送給 GPU 進行渲染,最後輸出到顯示器。整個過程大概需要幾十毫秒,但卡頓和其他延遲情況會增加延遲。
NVIDIA Reflex 2 首次採用了 Frame Warp 技術,是另一種減少延遲的方法。當一個幀被 GPU 渲染時,CPU 會根據最新滑鼠或手把輸入計算工作流程中下一幀的視角位置。 Frame Warp 從 CPU 採樣新的視角位置,然後將 GPU 剛才渲染的幀扭轉到最新的視角位置。在渲染幀被發送到顯示器之前,在盡可能最新的時間進行扭轉操作,確保螢幕上反映最新滑鼠輸入。
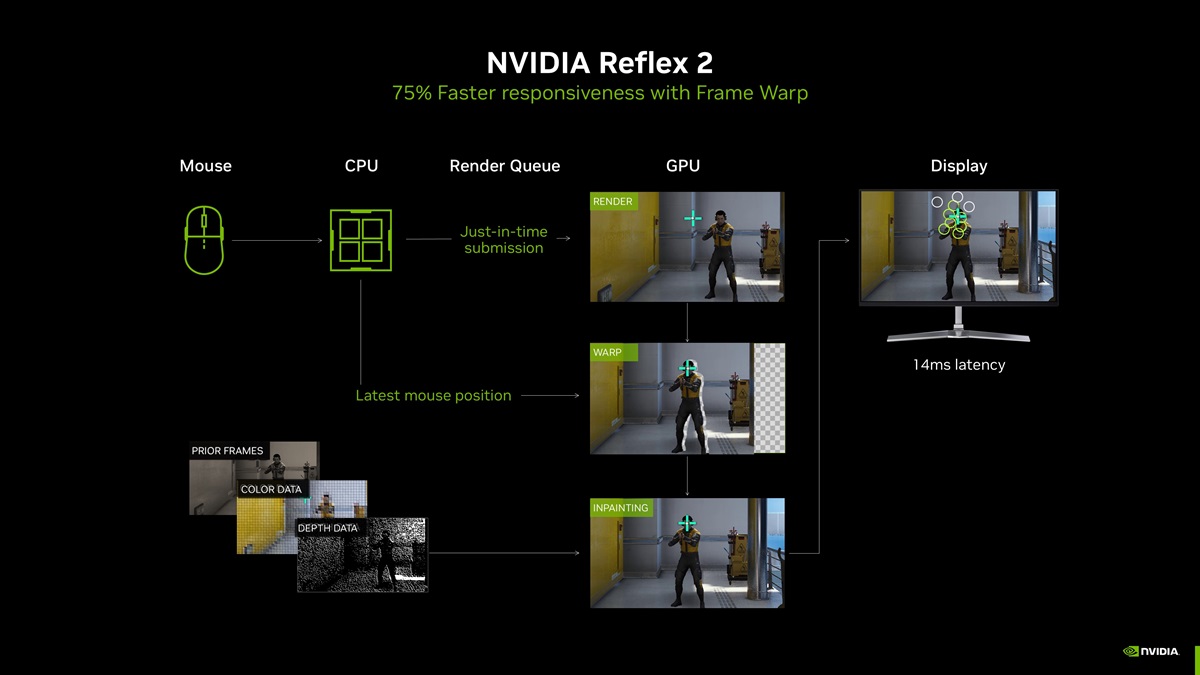
當 Frame Warp 轉移遊戲像素時,影像中會產生縫隙撕裂的空白像素,鏡頭位置的變化會讓遊戲場景中顯示先前沒有渲染的新像素。 NVIDIA 開發了一種優化了延遲的預測渲染演算法,使用先前影格的視角、顏色和深度數據,對這些撕裂的空白像素進行準確的影像修復。玩家可以透過更新的視角看到沒有撕裂的渲染幀,並降低了改變遊戲內視角位置而產生的延遲。這有助於玩家更好地瞄準目標,更精準地追蹤敵人,並提高命中率。
Ada Lovelace 和之前的 GPU 架構上,在 H.264 和 H.265 影片中提供了對 4:2:0 色度採樣的支援,Blackwell 架構則增加了編碼和解碼 4:2:2 色度採樣視頻的能力,這將節省 CPU 的負擔,並加快創作速度。視訊檔案使用 YUV 顏色格式,與儲存紅色、綠色和藍色(RGB)值不同,顏色被儲存為亮度(Y)、藍差色度(U) 和紅差色度(V)。
在 YUV 4:2:2 影片中,完整的亮度值被保留,並且只保留原始色度顏色資訊的一半。一個 4:2:2 壓縮的幀只需要未壓縮的 4:4:4 幀資料量的 2/3,但相比 4:2:0 色度壓縮幀提供了兩倍的顏色解析度。這意味著能在保留更多色彩資訊的同時還能減少檔案大小和頻寬需求之間取得了更好的平衡,額外保留的色彩資訊對於 HDR 內容特別有幫助,能提升拍攝和編輯及色彩校正的品質。

Blackwell 架構 GPU 配備了第九代 NVENC,支援 H.264 / H.265 4:2:2 編碼的8位元和10位元視訊輸出。另外由於 RTX 50 系列顯示卡也升級支援 DisplayPort 2.1 UHBR20 輸出,單一頻道支援 20Gbps 頻寬,讓使用者可以體驗到令人驚嘆的 HDR 視覺效果、超高解析度和更流暢的遊戲體驗。
來源
Blackwell 架構加入神經渲染
NVIDIA 稱,目前對於畫面品質的追求已大幅超越了摩爾定律所能夠提供的運算性能,為此加入神經渲染勢在必行,這是電腦圖形學的下一個時代。透過將神經網路整合到渲染過程中,可以在效能、影像品質和互動性方面取得顯著進步,從而提供全新的沉浸式體驗。
在這次的 Blackwell 架構 GPU 上,新一代 Tensor Core 增加了對 FP4 浮點運算精確度的支援。 FP4 是一種較低的量化方法,類似於檔案壓縮,可以減少模型推理過程中資料儲存和運算量大小,提高運算效率,降低流程對記憶體的要求。與大多數預設使用的 FP16 相比,FP4 使用的記憶體不到一半,並使 RTX 50 系列 GPU 的效能相比上一代提升高達2倍。透過利用 NVIDIA Tensor Model Optimizer 提供的高級量化方法,這些增益幾乎不會影響輸出品質。
由於加入了神經渲染,Blackwell 架構 GPU 的 SM 設計也有了變化,與 Tensor Core 的結合變得更加緊密,以便在傳統渲染管線中加入 AI 相關的功能。同時 Shader Core 也不再區分處理 INT32 / FP32 以及僅 FP32 的部分,全部都可以操作 INT32 / FP32。透過傳統 Shader Core 與 Tensor Core 的進一步結合,打造出 RTX 神經著色器( RTX Neural Shaders ),將小型神經網路帶入可程式著色器中,應用範圍包括輻射快取、紋理壓縮、材質、輻射場等。
The RTX Neural Shaders SDK 讓開發者在 RTX AI PC 上訓練他們的遊戲資料和著色器程式碼,並使用 Tensor Cores 在運行時加速其神經表示和模型權重。在訓練過程中,神經遊戲資料與傳統資料的輸出進行比較,並經過多次循環進行最佳化。開發者可以使用 Slang(一種將大型複雜函數拆分為更易處理的小部分的著色語言),以此簡化訓練過程。
這項突破性技術用於三種應用:RTX 神經紋理壓縮、RTX 神經材質和神經網路輻射快取(NRC)。 RTX 神經紋理壓縮使用 AI 在不到一分鐘的時間內壓縮數千種紋理,在相同的視覺品質下可以節省高達7倍的記憶體佔用;RTX 神經材質是使用 AI 壓縮通常保留給離線材質的複雜著色器代碼,而這些材質由多層組成,處理速度可提升5倍;神經網絡輻射快取使用在實時遊戲數據上訓練的神經網絡,能更準確和高效計算遊戲場景中的間接光照,而大幅減少光線追蹤的計算量。
在 RT Core 方面, NVIIDA 主要提升了偵測光線、路徑與三角形相交的效能,現在偵測能夠以簇集方式進行,另外也有三角形簇集解壓縮引擎。其中新增支援 Linear-swept Spheres(LSS),可以減少渲染毛髮所需的幾何圖形數量,並使用球體代替三角形以獲得更準確的毛髮形狀擬合,具有更好的性能和較小的記憶體佔用。
依照 NVIDIA 的說法,相較於首次加入 RT Core 的 Turing 架構,新一代 Blackwell 架構光線、路徑與三角形相交的檢測效率大概提升至原來的8倍,同時相比上一代 Ada Lovelace 架構,能節省約 25% 的記憶體使用率。
考慮到 AI 在遊戲內的應用越來越普遍,如何分配顯示卡內部的多樣化工作成為了新的問題。為此 NVIDIA 在 Blackwell 架構 GPU 上加入了 AI Management Processor ,可以根據不同的實際情況調整資料處理的優先權,以提升反映速度,維持運算效率。對於廣泛應用的 DLSS 來說,可以多幀產生提供一致的畫面產生時間。
Blackwell 架構 GPU 除了整體設計的提升外,很重要一點是加入了對 GDDR7 的支援。與現有 GDDR6 所使用的 NRZ / PAM2 或 GDDT6X 的 PAM4 訊號編碼機制不同,GDDR7 採用的是 PAM3 訊號編碼機制。 NRZ / PAM2 每週期提供1位元的資料傳輸,PAM4 每週期提供2位元的資料傳輸,而 PAM3 每兩個週期的資料傳輸為3位元。整體而言,能夠降低耗電,頻寬也得到了再次提升。
NVIDIA 在電源效率上也下了不少功夫,不僅針對筆記型電腦使用的型號,桌上型電腦使用的 RTX 50 系列顯示卡也因此受惠。 NVIDIA 針對閒置運算單元,在原有基礎上加入了電源軌閘控(Rail Gating),可單獨微調非頻繁操作區域的供電狀況。
NVIDIA 表示,Blackwell 架構的頻率調整速度相比 Ada Lovelace 架構快了上千倍,進入睡眠狀態或喚醒速度也提升了數個量級。這不僅能節省約 50% 的能源消耗,也能更快迎合運算的需求,帶來更好的效能表現。
具備多幀生成功能的DLSS 4
NVIDIA DLSS 是一套由 RTX Tensor Core 驅動的神經渲染技術,可在提供清晰、高品質影像的同時提升幀率。在新一代 Blackwell 架構 GPU 上,引入了 DLSS 4,具備多幀生成功能,在每個傳統渲染的幀之間產生多達三個額外的幀。
DLSS 4 也引進了自2020年發布 DLSS 2.0 以來對其 AI 模型的最大升級,DLSS 光線重建、DLSS 超解析度和 DLAA 將由 Transformer 模型驅動,這是 Transformer 模型首次在圖形領域的即時應用。 DLSS Transformer 模型透過改進的時間穩定性、減少鬼影以及運動中的更高細節來提升影像品質。
DLSS 3 幀產生的 AI 模型使用遊戲數據,如運動矢向量和深度訊息,以及來自 RTX 40 系列光流加速器的光流場來產生一個額外的幀。這種方式產生多個幀的成本過高,因為每次產生新幀都需要光流加速器和 AI 模型,且效能開銷會限制 GPU,導致輸入幀率降低。
DLSS 4 多幀生成結合了多項 Blackwell 架構的硬體技術和 DLSS 創新,實現了多幀生成。新的幀生成 AI 模型快了40%,使用的記憶體減少了30%,並且只需每渲染一幀運行一次即可產生多個幀。 NVIDIA 透過用一個非常高效的 AI 模型取代硬體光流加速器來加速光流場的生成,顯著降低了生成額外幀的計算成本。
利用 Blackwell 架構 GPU 的第五代 Tensor Core,AI 處理效能提升了最多2.5倍。一旦產生了新的多個幀,它們就會被均勻地安排,以提供流暢的視覺體驗。過去 DLSS 3 幀產生使用基於 GPU 的幀調度,其變異性可能會隨著額外幀的增加而累積,導致每個幀之間的幀調度不一致,影響流暢性。
為了解決產生多個幀的複雜性,Blackwell 架構 GPU 使用 Flip Metering,將幀率邏輯轉移到顯示引擎中,使得 GPU 能夠更精確地管理顯示時間。同時顯示引擎也增強了兩倍的像素處理能力,以支援更高的解析度和更新率,從而實現具有 DLSS 4 的 Flip Metering。
對於遊戲和應用,DLSS 4 結合多幀生成、光線重建和超級解析度技術,將幀率提升至普通渲染的最高8倍,並在從幀生成升級到多幀生成時,進一步提高幀率高達1.7倍,性能提升效果非常明顯。
先前 DLSS 使用卷積神經網路(CNN)透過分析局部上下文並在連續幀中追蹤這些區域的變化來產生新像素,經過六年的持續改進,已經達到了極限。新的 DLSS Transformer 模型使用了視覺 Transformer 變壓器,自注意力機制操作能夠評估整個幀中每個像素的相對重要性,並且跨越多個幀。
DLSS Transformer 模型採用兩倍於 CNN 模型的參數來實現對場景的更深層理解,從而產生提供更高穩定性、減少鬼影、運動細節更多以及場景邊緣更平滑的像素。在密集的光線追蹤內容裡,新的 DLSS Transformer 模型能大幅提升影像質量,在複雜的光照條件下會有更明顯的優勢,穩定性會加強,重影會減少,閃爍現像也會消失。 DLSS 光線重建、DLSS 超解析度和 DLAA 將由 Transformer 模型驅動,這是 Transformer 模型首次在圖形領域的即時應用,它也將進一步提升 RTX 20 / 30 / 40 系列顯示卡的 DLSS 效能體驗。預計在未來數年裡,影像品質會持續提升。
尚未上市的 RTX 50 系列顯示卡已經可以在75款遊戲與應用程式中使用,並利用 DLSS 多幀生成技術實現效能倍增。遊戲的幀生成功能在 RTX 50 / 40 系列上也進行了升級,不僅提升了效能,也減少了記憶體的使用。
Reflex 2首次採用Frame Warp技術
在過去四年裡,NVIDIA Reflex 已整合到超過100款遊戲中,可以將 PC 延遲降低 50%。在新一代 Blackwell 架構 GPU 上,帶來了 NVIDIA Reflex 2,結合了 Reflex 低延遲模式和新的 Frame Warp 技術,透過把最新的滑鼠輸入指令及時同步給渲染幀,及時更新渲染的遊戲幀並在渲染幀被發送到顯示器之前獲取最新的滑鼠訊息,透過刷新渲染的遊戲幀以進一步減少延遲,將 PC 延遲進一步降低多達 75%。
在遊戲裡,玩家的每個動作都會經過複雜的計算,然後在螢幕上顯示,其中的每一步都會增加延遲。來自鍵盤和滑鼠的輸入傳輸給遊戲,由 CPU 進行計算其在遊戲中的效果。操作的結果被置於渲染佇列中,佇列傳送給 GPU 進行渲染,最後輸出到顯示器。整個過程大概需要幾十毫秒,但卡頓和其他延遲情況會增加延遲。
NVIDIA Reflex 2 首次採用了 Frame Warp 技術,是另一種減少延遲的方法。當一個幀被 GPU 渲染時,CPU 會根據最新滑鼠或手把輸入計算工作流程中下一幀的視角位置。 Frame Warp 從 CPU 採樣新的視角位置,然後將 GPU 剛才渲染的幀扭轉到最新的視角位置。在渲染幀被發送到顯示器之前,在盡可能最新的時間進行扭轉操作,確保螢幕上反映最新滑鼠輸入。
當 Frame Warp 轉移遊戲像素時,影像中會產生縫隙撕裂的空白像素,鏡頭位置的變化會讓遊戲場景中顯示先前沒有渲染的新像素。 NVIDIA 開發了一種優化了延遲的預測渲染演算法,使用先前影格的視角、顏色和深度數據,對這些撕裂的空白像素進行準確的影像修復。玩家可以透過更新的視角看到沒有撕裂的渲染幀,並降低了改變遊戲內視角位置而產生的延遲。這有助於玩家更好地瞄準目標,更精準地追蹤敵人,並提高命中率。
4:2:2 H.264 / H265 影片編解碼支援
Ada Lovelace 和之前的 GPU 架構上,在 H.264 和 H.265 影片中提供了對 4:2:0 色度採樣的支援,Blackwell 架構則增加了編碼和解碼 4:2:2 色度採樣視頻的能力,這將節省 CPU 的負擔,並加快創作速度。視訊檔案使用 YUV 顏色格式,與儲存紅色、綠色和藍色(RGB)值不同,顏色被儲存為亮度(Y)、藍差色度(U) 和紅差色度(V)。
在 YUV 4:2:2 影片中,完整的亮度值被保留,並且只保留原始色度顏色資訊的一半。一個 4:2:2 壓縮的幀只需要未壓縮的 4:4:4 幀資料量的 2/3,但相比 4:2:0 色度壓縮幀提供了兩倍的顏色解析度。這意味著能在保留更多色彩資訊的同時還能減少檔案大小和頻寬需求之間取得了更好的平衡,額外保留的色彩資訊對於 HDR 內容特別有幫助,能提升拍攝和編輯及色彩校正的品質。
Blackwell 架構 GPU 配備了第九代 NVENC,支援 H.264 / H.265 4:2:2 編碼的8位元和10位元視訊輸出。另外由於 RTX 50 系列顯示卡也升級支援 DisplayPort 2.1 UHBR20 輸出,單一頻道支援 20Gbps 頻寬,讓使用者可以體驗到令人驚嘆的 HDR 視覺效果、超高解析度和更流暢的遊戲體驗。
來源




