
NVIDIA 正式發布了新一代 Ampere RTX 30 系列顯卡,在效能上有相當大的躍進,雖然說還未有看到實測,但就官方公布的數據是如此,連 RTX 3070 都可以超越過上一代旗艦的 RTX 2080 Ti,至於為何會有顯著的效能提升 Expreview 進行了簡要的分析。

Turing 架構是 NVIDIA 的初代 RTX 架構,它首次引入了 RT Core,並升級了從 Volta 架構開始引入的 Tensor Core。
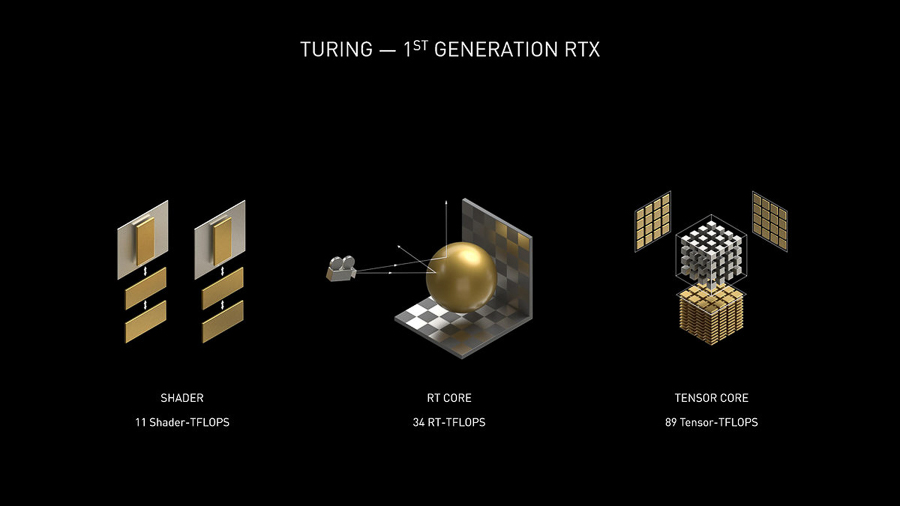
它的意義在於將整個 GPU 的處理管線分成多個部分,早前的 GPU 只需要全力渲染畫面即可,而在引入實時光線追踪特效之後,GPU 中的處理核心需要分心去算光線追踪特效,偏偏這部分又非常吃算力,會讓傳統的 GPU 浪費非常多的算力。
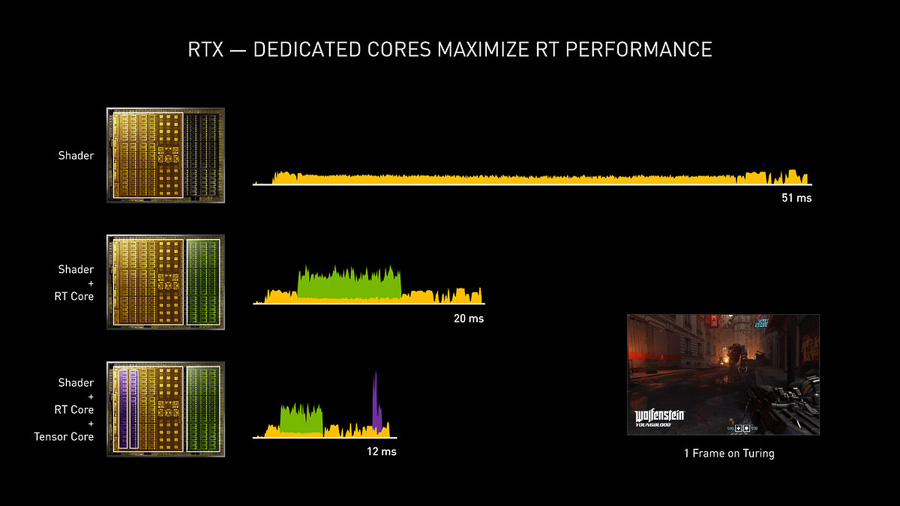
於是 NVIDIA 為即時光線追踪引入獨立的硬體處理管線,也就是 RT Core。但在開啟即時光線追踪的情況下,單靠 RT Core 加速仍然沒法達成高幀數的目標,所以 NVIDIA 研發了 DLSS 超級採樣技術,也就是利用機器學習,通過 AI 的方式將低解析度的遊戲圖像即時處理成高解析的圖像輸出。因為降低了實際的渲染解析度,所以大幅減輕了 GPU 的計算壓力,從而達成開啟即時光追下的流暢遊戲。
.
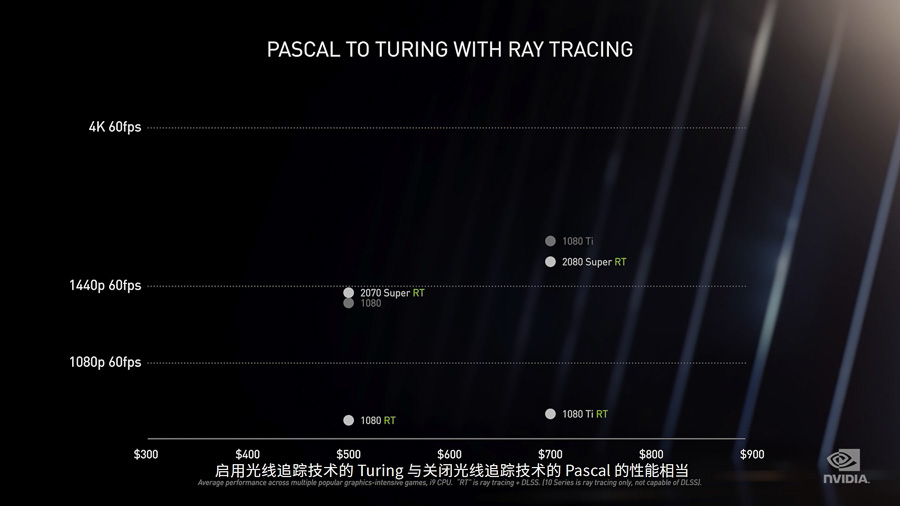
但是,Turing 顯卡的一大問題就是計算規模不夠大,老黃在發布上也很坦誠的說,開了光追的 Turing 顯卡表現和沒開光追的 Pascal 差不太多(從圖上甚至可以看到 GTX 1080 Ti 在非光追情況下的表現要優於光追場景下的 RTX 2080 Super)。
新的 Ampere 遊戲顯卡與 A100 加速卡上那枚使用台積電 N7 製程的 GA100 晶片不同,NVIDIA 選擇和三星合作,定制了基於三星 8nm 製程,稱為 Samsung 8N(N for NVIDIA)。在面積最大的 GA102 晶片中,NVIDIA 塞入了280億個晶體管,這個數字是 TU102 的1.5倍,但仍然比面向計算用途的 GA100 少很多(542億)。

這多出來的1.5倍晶體管主要被用在加倍 FP32 單元上,從 NVIDIA 官網上的對比表我們即可看到這一明顯的區別點。
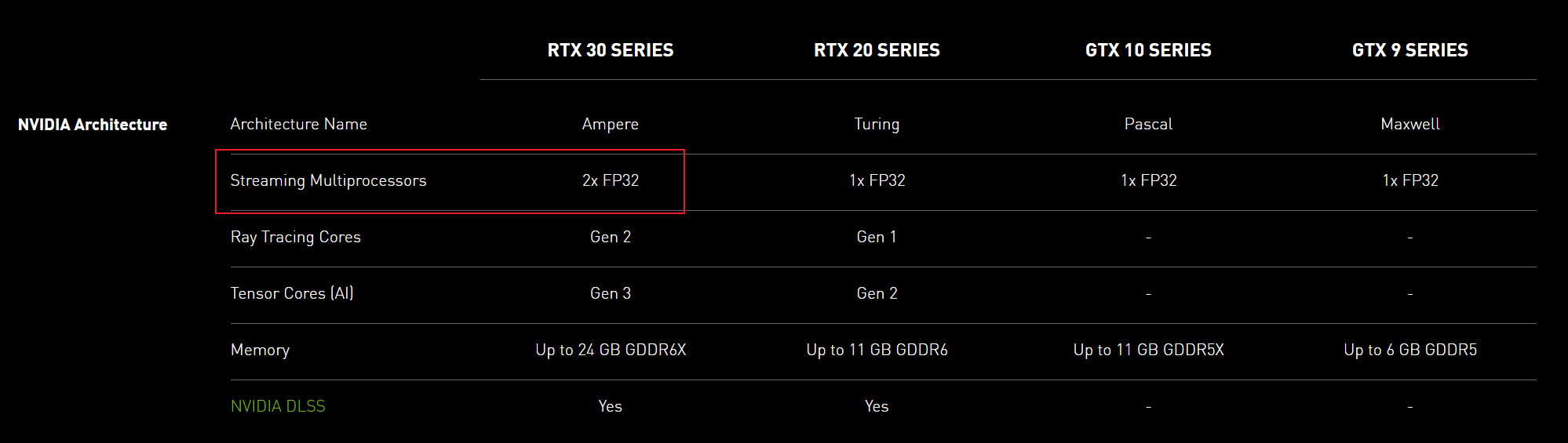
以往在 NVIDIA 的 GPU 中,一個 CUDA Core 對應一個 FP32 計算單元,在 Turing GPU 上面,NVIDIA 加入了獨立的整數計算單元,它與傳統 FP32 計算單元的比例是1:1,到了 Ampere 上,因為對算力有非常高的需求,NVIDIA 直接選擇把 FP32 單元的數量翻倍。並且官方並沒有採用一個 CUDA Core 對應兩個 FP32 單元的計數方式,仍然保留了1:1的算法,所以這一代的 CUDA 核心數量之所以暴漲,下表對幾代同級顯卡的 CUDA 核心數量進行了對比:
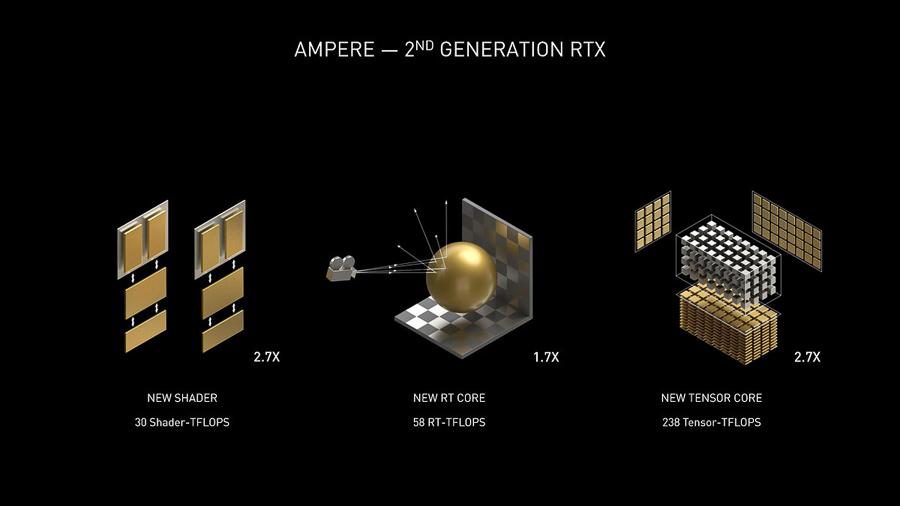
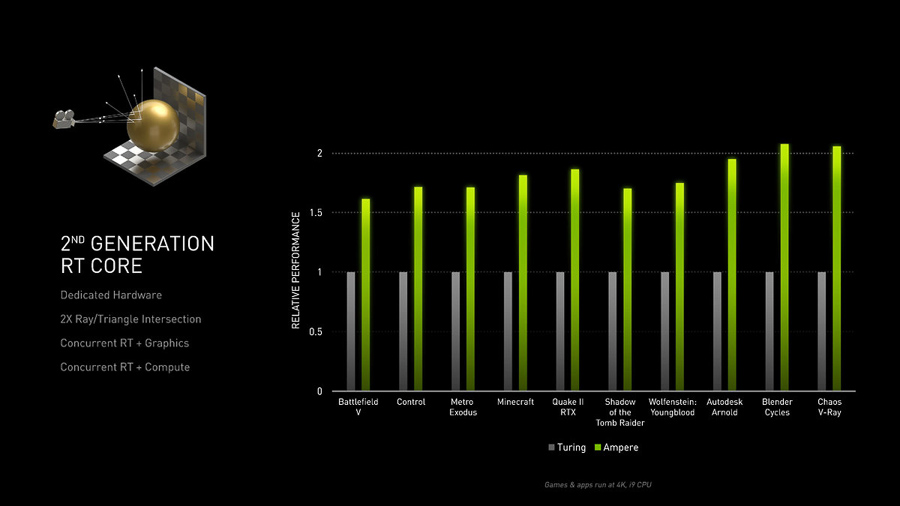
從上表中可以看到 RTX 30 顯卡在計算規模上的暴增,不過這只是它效能增幅來源的一個部分。NVIDIA 還引入了第二代 RT Core 和第三代 Tensor Core。新的 RT Core 在處理光線追踪相關的計算時,可達到初代 RT Core 的1.7x效率,而 GA100 的同款 Tensor Core 則帶來了2.7x的 AI 效能提升。
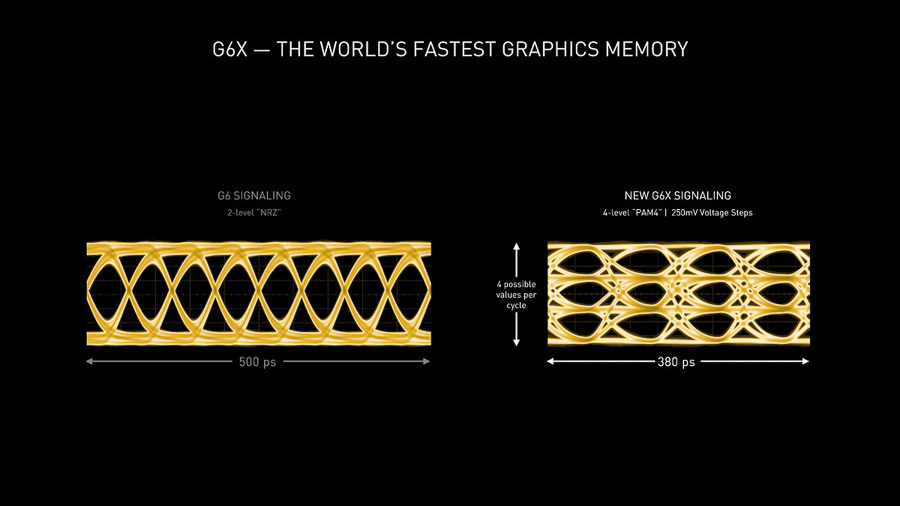
另外還有搭配了新的記憶體。RTX 3080 和 RTX 3090 都使用了來自於美光的 GDDR6X,在記憶體帶寬上逼近1TB/s的大關。這多個方面的技術添加,也讓 RTX 30 系列顯卡擁有最大世代躍進的效能表現。
Ampere GPU 在能耗比上達成了一個1.9x的進步,在半導體製程提升日益困難的今天,這個進步幅度已經算是不小了。但是從下圖上也可以看到,Ampere 顯卡在功耗上也比 Turing 要提高不少。

來源
Turing 架構是 NVIDIA 的初代 RTX 架構,它首次引入了 RT Core,並升級了從 Volta 架構開始引入的 Tensor Core。
它的意義在於將整個 GPU 的處理管線分成多個部分,早前的 GPU 只需要全力渲染畫面即可,而在引入實時光線追踪特效之後,GPU 中的處理核心需要分心去算光線追踪特效,偏偏這部分又非常吃算力,會讓傳統的 GPU 浪費非常多的算力。
於是 NVIDIA 為即時光線追踪引入獨立的硬體處理管線,也就是 RT Core。但在開啟即時光線追踪的情況下,單靠 RT Core 加速仍然沒法達成高幀數的目標,所以 NVIDIA 研發了 DLSS 超級採樣技術,也就是利用機器學習,通過 AI 的方式將低解析度的遊戲圖像即時處理成高解析的圖像輸出。因為降低了實際的渲染解析度,所以大幅減輕了 GPU 的計算壓力,從而達成開啟即時光追下的流暢遊戲。
.
但是,Turing 顯卡的一大問題就是計算規模不夠大,老黃在發布上也很坦誠的說,開了光追的 Turing 顯卡表現和沒開光追的 Pascal 差不太多(從圖上甚至可以看到 GTX 1080 Ti 在非光追情況下的表現要優於光追場景下的 RTX 2080 Super)。
新的 Ampere 遊戲顯卡與 A100 加速卡上那枚使用台積電 N7 製程的 GA100 晶片不同,NVIDIA 選擇和三星合作,定制了基於三星 8nm 製程,稱為 Samsung 8N(N for NVIDIA)。在面積最大的 GA102 晶片中,NVIDIA 塞入了280億個晶體管,這個數字是 TU102 的1.5倍,但仍然比面向計算用途的 GA100 少很多(542億)。
這多出來的1.5倍晶體管主要被用在加倍 FP32 單元上,從 NVIDIA 官網上的對比表我們即可看到這一明顯的區別點。
以往在 NVIDIA 的 GPU 中,一個 CUDA Core 對應一個 FP32 計算單元,在 Turing GPU 上面,NVIDIA 加入了獨立的整數計算單元,它與傳統 FP32 計算單元的比例是1:1,到了 Ampere 上,因為對算力有非常高的需求,NVIDIA 直接選擇把 FP32 單元的數量翻倍。並且官方並沒有採用一個 CUDA Core 對應兩個 FP32 單元的計數方式,仍然保留了1:1的算法,所以這一代的 CUDA 核心數量之所以暴漲,下表對幾代同級顯卡的 CUDA 核心數量進行了對比:
| 型號 | RTX 3090 | RTX 2080 Ti | GTX 1080 Ti | RTX 3080 | RTX 2080 | GTX 1080 | RTX 3070 | RTX 2070 | GTX 1070 |
|---|---|---|---|---|---|---|---|---|---|
| CUDA核心數量 | 10496 | 4352 | 3584 | 8704 | 2944 | 2560 | 5888 | 2304 | 1920 |
| FP32單元數量 | 10496 | 4352 | 3584 | 8704 | 2944 | 2560 | 5888 | 2304 | 1920 |
| INT單元數量 | 5248 | 4352 | N/A | 4352 | 2944 | N/A | 2944 | 2304 | N/A |
從上表中可以看到 RTX 30 顯卡在計算規模上的暴增,不過這只是它效能增幅來源的一個部分。NVIDIA 還引入了第二代 RT Core 和第三代 Tensor Core。新的 RT Core 在處理光線追踪相關的計算時,可達到初代 RT Core 的1.7x效率,而 GA100 的同款 Tensor Core 則帶來了2.7x的 AI 效能提升。
另外還有搭配了新的記憶體。RTX 3080 和 RTX 3090 都使用了來自於美光的 GDDR6X,在記憶體帶寬上逼近1TB/s的大關。這多個方面的技術添加,也讓 RTX 30 系列顯卡擁有最大世代躍進的效能表現。
Ampere GPU 在能耗比上達成了一個1.9x的進步,在半導體製程提升日益困難的今天,這個進步幅度已經算是不小了。但是從下圖上也可以看到,Ampere 顯卡在功耗上也比 Turing 要提高不少。
來源






