
先前有關於GTX 970顯卡只能使用3.5GB記憶體的問題,NVIDIA對此也作出了解釋,說這是設計使然。但官方回答並沒有詳細解釋為什麼要這麼做,現在這個問題的內幕被深挖出來了,NVIDIA在GTX 970顯卡的規格上存在錯誤,其ROP單元及L2並非當初所說,而是做了精簡。

Anandtech網站對GTX 970顯卡的3.5GB記憶體問題做了深入研究,在跟NVIDIA探討之後澄清了一些目前存在的問題。
GTX 970規格修正:ROP及L2有精簡
首先要搞清的一個問題是,NVIDIA此前在官方文檔中介紹的GTX 970規格是有錯誤的,它跟GTX 980一樣使用了GM204核心,之前NVIDIA只說其SMM單元屏蔽了三組以降低功耗,7GHz GDDR5、256bit及64 ROP單元保留,但實際上有些規格是錯誤的。
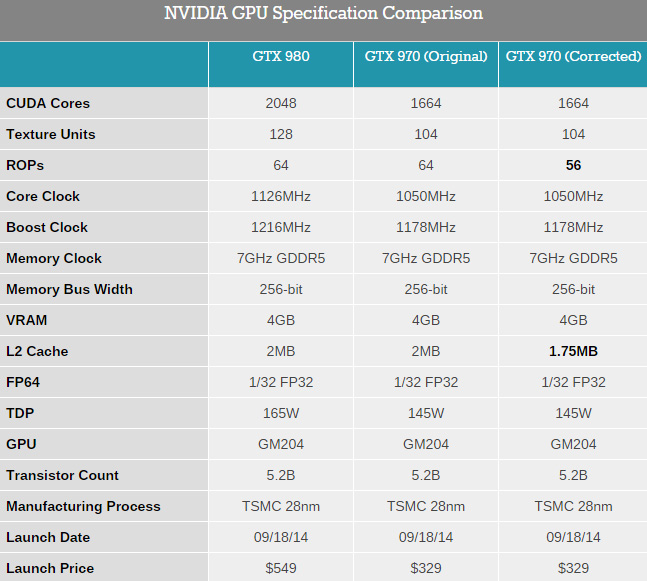
GTX 970記憶體異常的背後必然有規格上的差異,現在NVIDIA已經承認了當初的GTX 970規格說明是有錯誤的,4個ROP/記憶體控制分區中實際上有1個被禁用了,所以它的實際ROP單元只有56個,L2也不是當初說的2MB而是1.75MB,少了1/8,不過記憶體控制器沒有變化,確實是256bit 4GB。部分禁用ROP/記憶體主控的功能是Maxwell架構上才有的新功能。
GTX 970禁用三組SMM單元,同時部分單元功能也受影響了
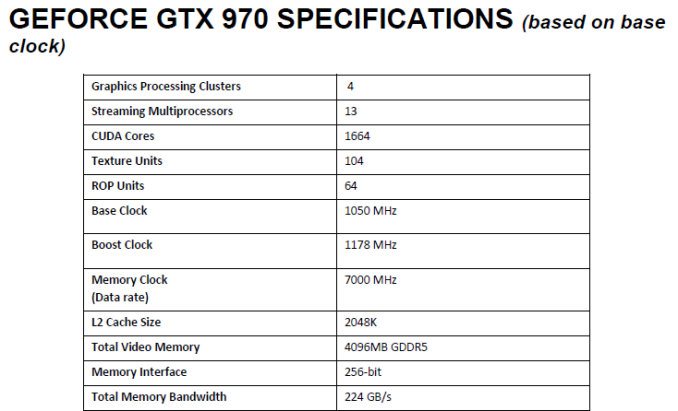
當初NVIDIA文檔上介紹的GTX 970規格
至於為什麼會出現這樣的錯誤,NVIDIA的解釋稱這是偶然的,這些文檔資料都是NVIDIA的技術銷售團隊做的。NVIDIA解釋說技術銷售團隊在製作評測指南時並沒有意識到Maxwell架構具備上面提及的“部分禁止”功能,他們知道GTX 970是有256bit,但不知道可以獨立禁止ROP單元及2MB L2,所以他們製作的文檔中的錯誤就在NVIDIA各部門流傳開了,並通過媒體傳播開了。
這個問題在過去的4個月中都沒有被發現,直到本月初NVIDIA開始調查GTX 970記憶體尋址的問題時才被注意到。NVIDIA現在做的無疑是危機公關,Anandtech表示考慮到NVIDIA幾乎不是第一家在危機公關時撒謊的公司,應該相信他們嗎?
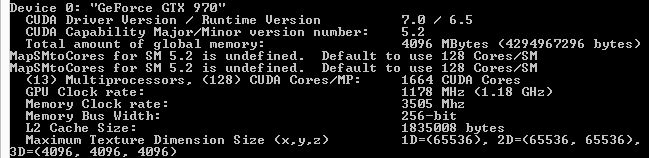
這些問題其實之前也暴露出了一些蛛絲馬跡,比如NVIDIA的CUDA DeviceQuery工具之前已經報告GTX 970顯卡的L2是1.75MB,而GTX 980是2MB。
深度解析:Maxwell架構的顯存交叉及ROP分區
出問題的是GTX 970,因為在Maxwell架構NVIDIA才開始禁用部分ROP/記憶體主控分區,之前的Kepler及更早的架構都沒有這個能力。而GTX 970禁用了部分分區,所以它的行為跟GTX 980或者理論上的Maxwell架構有所不同。
NVIDIA之前的解釋也提到了這一點,禁用部分單元導致GTX 970的ROP/記憶體主控分區不平衡,所以NVIDIA設計了記憶體分區,3.5GB的這部分是高性能分區,0.5GB那部分包含了剩餘的記憶體,性能略低。
為了更好地理解上面的差異,首先我們要先了解Maxwell架構的內存交叉( memory crossbar),看看他們是如何工作的。
GTX 970顯卡的內存交叉問題
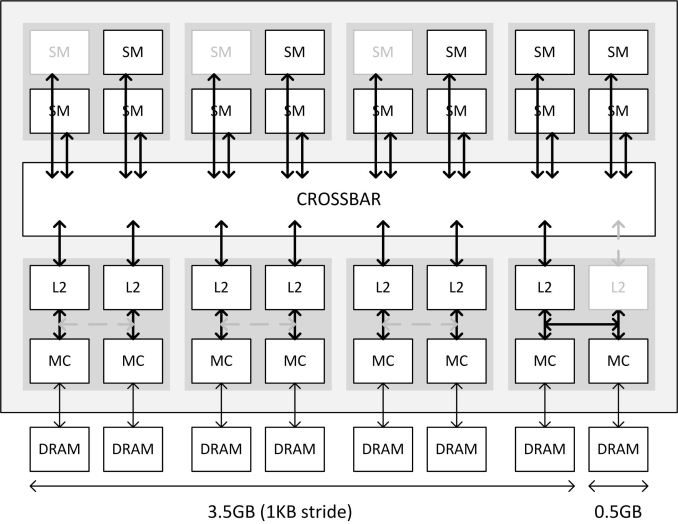
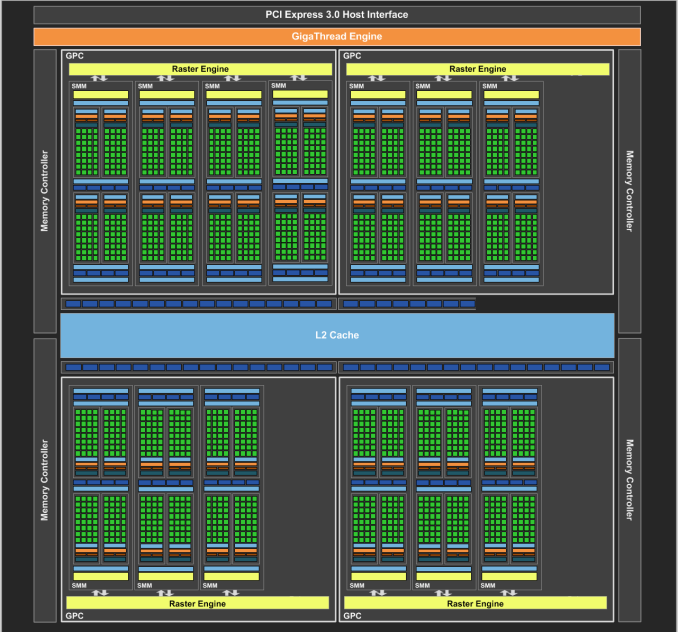
NVIDIA在上圖中闡述了Maxwell架構的記憶體交叉佈局,特別是GTX 970如何配置的。Crossbar上面是16組SMM單元,下面則是4組ROP/主控分區,每個分區都被分配到特定的ROP/L2單元及記憶體主控中。需要注意的是,GTX 970屏蔽的三組SMM單元並不是1/3/5組這麼簡單,L2也不是屏蔽了最後一組,不過這裡是示意圖,我們不需要考慮到底是那些單元被屏蔽了。
上面的示意圖顯示了SMM單元及ROP/主控分區是如何通過Crossbar連接的,記憶體分區主要是跟ROP/主控分區有關,而SMM單元實際上在GTX 970顯卡的記憶體分配無關——Crossbar將他們聯繫在一起,而Croosbar只跟ROP/主控分區有關。
在GTX 970顯卡上的情況是Maxwell架構首次使用這種部分禁用的新功能,NVIDIA禁用了1組ROP/L2單元,去掉了8個ROP單元(或者說是1組8pixel/clock的單元)以及256KB L2,這就是GTX 970為什麼只有56個ROP單元、175MB L2。
Kepler與Maxwell架構的區別

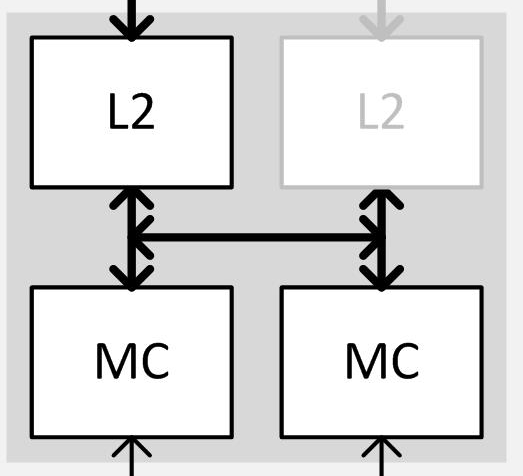
與此同時,這還有一個新功能,但它只有在禁用部分分區時才會啟用,這就是第一、第二個ROP分區之間的Link。通常每個ROP/L2單元都需要1個接口連接到Crossbar,同時需要1個Link連接到它自己的32位記憶體控制器通道中。不過GTX 970禁用了1組ROP/L2單元,所以臨近的Link(buddy link)開始發揮作用,這是Maxwell架構能夠禁用部分分區的關鍵,它能讓第二個只有一半的記憶體主控保持啟用狀態。
這個Link只有在ROP/L2單元被禁用時才會需要被啟用,NVIDIA確認它跟正常的ROP/L2單元到MC主控的link一樣都是全帶寬的,每週期可以執行4個32bytes要求(2讀2寫)。總之,這個Link是保證禁用部分分區功能的關鍵,它也使得在缺少了1組ROP/L2單元之後還能使用完整256bit頻寬成為了可能。
與GPU執行每個操作類似,記憶體讀取也會支持並行操作以提高吞吐量。在GTX 980這樣完整的顯卡上,這些操作是以1KB的步幅匹配於所有記憶體控制器的。為了實現這個設計,每個32bit記憶體通道都需要通過自己的ROP/L2單元用一個直接的Link連接Crossbar。在GTX 970上,它有7個Crossbar接口和8個記憶體通道。
最後,由於Crossbar和記憶體主控的設計,1個Crossbar接口不能承載2個記憶體通道的完全負載,Crossbar和它自己的ROP/L2單元可以同時連接兩個記憶體通道,分裂4個算法,不過同時只有1個讀取返回總線,因此實際情況中它只能讀取1個記憶體通道。
(以下是比較白話的解釋)
正因為此,NVIDIA才將GTX 970顯卡的記憶體分為兩個分區,正常的3.5GB和另外的500MB分區,前面的3.5GB部分,其功能跟正常的GTX 980顯卡是一樣的,以1KB步進匹配7個Crossbar接口,因此有7個DRAM模塊。第八個DRAM模組包含500MB分區,需要自己的Crossbar。
這就是為什麼GTX 970顯卡的224GB/s頻寬在技術上正確的,但3.5GB部分的頻寬是196GB/s(7GHz*7port*32bit),而500MB那部分讀取速度是28GB/s,但這二者不是同時讀取的,這實際上是一個XOR(亦或)的情況。進一步來講,由於500MB記憶體那部分不能跟3.5GB那部分同時讀取,這又進一步導致顯卡的頻寬過低,使用的500MB部分記憶體越多,3.5GB部分的等效頻寬就會越低。
最終的結果就是GTX 970擁有獨一無二的記憶體佈局,需要操作系統及NVIDIA的驅動優化,因為3.5GB部分的記憶體相比另外的500MB部分更大,更快,更好。這500MB部分的邏輯上來看相當於VRAM與系統記憶體之間的快取,它的速度比3.5GB部分更慢,不過依然是PCI-E總線到記憶體頻寬的2倍。
GTX 970是NVIDIA首次使用ROP/MC主控分區的產品,不過這並不是NVIDIA首次次用分區記憶體或者非對稱配置了。從GTX 500系列NVIDIA就開始應用非對稱/異構記憶體配置了,特別是在GTX 660及GTX 660 Ti上了。這些顯卡上使用了192bit,但搭配了2GB,這也意味著有些記憶體主控會比其他主控連著更多VRAM。
GTX 660 Ti 上使用過類似的異構記憶體
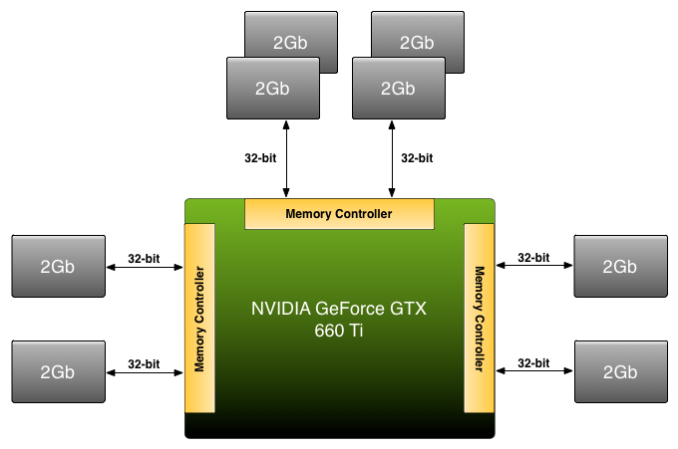

最終的結果也是類似的,不過NVIDIA從來沒有深度解釋這些顯卡的記憶體尋址,看起來跟GTX 970的情況很類似。與其說NVIDIA有過多次這樣的經驗,不如說這是NVIDIA首次在GTX 970這樣的高端顯卡上使用這種方式。
往大的方面說,取決於你如何定義GTX 970的記憶體容量,它可以說是3.5GB,也可以說是4GB,其中只有前面的3.5GB是全速的。不過512MB那部分分區也是有意義的,雖然性能比3.5GB部分低,但它依然比PCI-E到主記憶體的頻寬高,GTX 970依然可以使用完整的4GB。
來源:
http://anandtech.com/show/8935/geforce-gtx-970-correcting-the-specs-exploring-memory-allocation
http://www.expreview.com/38545-all.html
Anandtech網站對GTX 970顯卡的3.5GB記憶體問題做了深入研究,在跟NVIDIA探討之後澄清了一些目前存在的問題。
GTX 970規格修正:ROP及L2有精簡
首先要搞清的一個問題是,NVIDIA此前在官方文檔中介紹的GTX 970規格是有錯誤的,它跟GTX 980一樣使用了GM204核心,之前NVIDIA只說其SMM單元屏蔽了三組以降低功耗,7GHz GDDR5、256bit及64 ROP單元保留,但實際上有些規格是錯誤的。
GTX 970記憶體異常的背後必然有規格上的差異,現在NVIDIA已經承認了當初的GTX 970規格說明是有錯誤的,4個ROP/記憶體控制分區中實際上有1個被禁用了,所以它的實際ROP單元只有56個,L2也不是當初說的2MB而是1.75MB,少了1/8,不過記憶體控制器沒有變化,確實是256bit 4GB。部分禁用ROP/記憶體主控的功能是Maxwell架構上才有的新功能。
GTX 970禁用三組SMM單元,同時部分單元功能也受影響了
當初NVIDIA文檔上介紹的GTX 970規格
至於為什麼會出現這樣的錯誤,NVIDIA的解釋稱這是偶然的,這些文檔資料都是NVIDIA的技術銷售團隊做的。NVIDIA解釋說技術銷售團隊在製作評測指南時並沒有意識到Maxwell架構具備上面提及的“部分禁止”功能,他們知道GTX 970是有256bit,但不知道可以獨立禁止ROP單元及2MB L2,所以他們製作的文檔中的錯誤就在NVIDIA各部門流傳開了,並通過媒體傳播開了。
這個問題在過去的4個月中都沒有被發現,直到本月初NVIDIA開始調查GTX 970記憶體尋址的問題時才被注意到。NVIDIA現在做的無疑是危機公關,Anandtech表示考慮到NVIDIA幾乎不是第一家在危機公關時撒謊的公司,應該相信他們嗎?
這些問題其實之前也暴露出了一些蛛絲馬跡,比如NVIDIA的CUDA DeviceQuery工具之前已經報告GTX 970顯卡的L2是1.75MB,而GTX 980是2MB。
深度解析:Maxwell架構的顯存交叉及ROP分區
出問題的是GTX 970,因為在Maxwell架構NVIDIA才開始禁用部分ROP/記憶體主控分區,之前的Kepler及更早的架構都沒有這個能力。而GTX 970禁用了部分分區,所以它的行為跟GTX 980或者理論上的Maxwell架構有所不同。
NVIDIA之前的解釋也提到了這一點,禁用部分單元導致GTX 970的ROP/記憶體主控分區不平衡,所以NVIDIA設計了記憶體分區,3.5GB的這部分是高性能分區,0.5GB那部分包含了剩餘的記憶體,性能略低。
為了更好地理解上面的差異,首先我們要先了解Maxwell架構的內存交叉( memory crossbar),看看他們是如何工作的。
GTX 970顯卡的內存交叉問題
NVIDIA在上圖中闡述了Maxwell架構的記憶體交叉佈局,特別是GTX 970如何配置的。Crossbar上面是16組SMM單元,下面則是4組ROP/主控分區,每個分區都被分配到特定的ROP/L2單元及記憶體主控中。需要注意的是,GTX 970屏蔽的三組SMM單元並不是1/3/5組這麼簡單,L2也不是屏蔽了最後一組,不過這裡是示意圖,我們不需要考慮到底是那些單元被屏蔽了。
上面的示意圖顯示了SMM單元及ROP/主控分區是如何通過Crossbar連接的,記憶體分區主要是跟ROP/主控分區有關,而SMM單元實際上在GTX 970顯卡的記憶體分配無關——Crossbar將他們聯繫在一起,而Croosbar只跟ROP/主控分區有關。
在GTX 970顯卡上的情況是Maxwell架構首次使用這種部分禁用的新功能,NVIDIA禁用了1組ROP/L2單元,去掉了8個ROP單元(或者說是1組8pixel/clock的單元)以及256KB L2,這就是GTX 970為什麼只有56個ROP單元、175MB L2。
Kepler與Maxwell架構的區別
與此同時,這還有一個新功能,但它只有在禁用部分分區時才會啟用,這就是第一、第二個ROP分區之間的Link。通常每個ROP/L2單元都需要1個接口連接到Crossbar,同時需要1個Link連接到它自己的32位記憶體控制器通道中。不過GTX 970禁用了1組ROP/L2單元,所以臨近的Link(buddy link)開始發揮作用,這是Maxwell架構能夠禁用部分分區的關鍵,它能讓第二個只有一半的記憶體主控保持啟用狀態。
這個Link只有在ROP/L2單元被禁用時才會需要被啟用,NVIDIA確認它跟正常的ROP/L2單元到MC主控的link一樣都是全帶寬的,每週期可以執行4個32bytes要求(2讀2寫)。總之,這個Link是保證禁用部分分區功能的關鍵,它也使得在缺少了1組ROP/L2單元之後還能使用完整256bit頻寬成為了可能。
與GPU執行每個操作類似,記憶體讀取也會支持並行操作以提高吞吐量。在GTX 980這樣完整的顯卡上,這些操作是以1KB的步幅匹配於所有記憶體控制器的。為了實現這個設計,每個32bit記憶體通道都需要通過自己的ROP/L2單元用一個直接的Link連接Crossbar。在GTX 970上,它有7個Crossbar接口和8個記憶體通道。
最後,由於Crossbar和記憶體主控的設計,1個Crossbar接口不能承載2個記憶體通道的完全負載,Crossbar和它自己的ROP/L2單元可以同時連接兩個記憶體通道,分裂4個算法,不過同時只有1個讀取返回總線,因此實際情況中它只能讀取1個記憶體通道。
(以下是比較白話的解釋)
正因為此,NVIDIA才將GTX 970顯卡的記憶體分為兩個分區,正常的3.5GB和另外的500MB分區,前面的3.5GB部分,其功能跟正常的GTX 980顯卡是一樣的,以1KB步進匹配7個Crossbar接口,因此有7個DRAM模塊。第八個DRAM模組包含500MB分區,需要自己的Crossbar。
這就是為什麼GTX 970顯卡的224GB/s頻寬在技術上正確的,但3.5GB部分的頻寬是196GB/s(7GHz*7port*32bit),而500MB那部分讀取速度是28GB/s,但這二者不是同時讀取的,這實際上是一個XOR(亦或)的情況。進一步來講,由於500MB記憶體那部分不能跟3.5GB那部分同時讀取,這又進一步導致顯卡的頻寬過低,使用的500MB部分記憶體越多,3.5GB部分的等效頻寬就會越低。
最終的結果就是GTX 970擁有獨一無二的記憶體佈局,需要操作系統及NVIDIA的驅動優化,因為3.5GB部分的記憶體相比另外的500MB部分更大,更快,更好。這500MB部分的邏輯上來看相當於VRAM與系統記憶體之間的快取,它的速度比3.5GB部分更慢,不過依然是PCI-E總線到記憶體頻寬的2倍。
GTX 970是NVIDIA首次使用ROP/MC主控分區的產品,不過這並不是NVIDIA首次次用分區記憶體或者非對稱配置了。從GTX 500系列NVIDIA就開始應用非對稱/異構記憶體配置了,特別是在GTX 660及GTX 660 Ti上了。這些顯卡上使用了192bit,但搭配了2GB,這也意味著有些記憶體主控會比其他主控連著更多VRAM。
GTX 660 Ti 上使用過類似的異構記憶體
最終的結果也是類似的,不過NVIDIA從來沒有深度解釋這些顯卡的記憶體尋址,看起來跟GTX 970的情況很類似。與其說NVIDIA有過多次這樣的經驗,不如說這是NVIDIA首次在GTX 970這樣的高端顯卡上使用這種方式。
往大的方面說,取決於你如何定義GTX 970的記憶體容量,它可以說是3.5GB,也可以說是4GB,其中只有前面的3.5GB是全速的。不過512MB那部分分區也是有意義的,雖然性能比3.5GB部分低,但它依然比PCI-E到主記憶體的頻寬高,GTX 970依然可以使用完整的4GB。
來源:
http://anandtech.com/show/8935/geforce-gtx-970-correcting-the-specs-exploring-memory-allocation
http://www.expreview.com/38545-all.html