
NVIDIA 在 GTC 2020 線上演說正式發布了 GA100 GPU,基於新一代 Ampere 的 A100 加速計算卡和基於 A100 加速卡的新一代 DGX A100 AI 計算系統。
完整版的GA100核心架構圖如下:
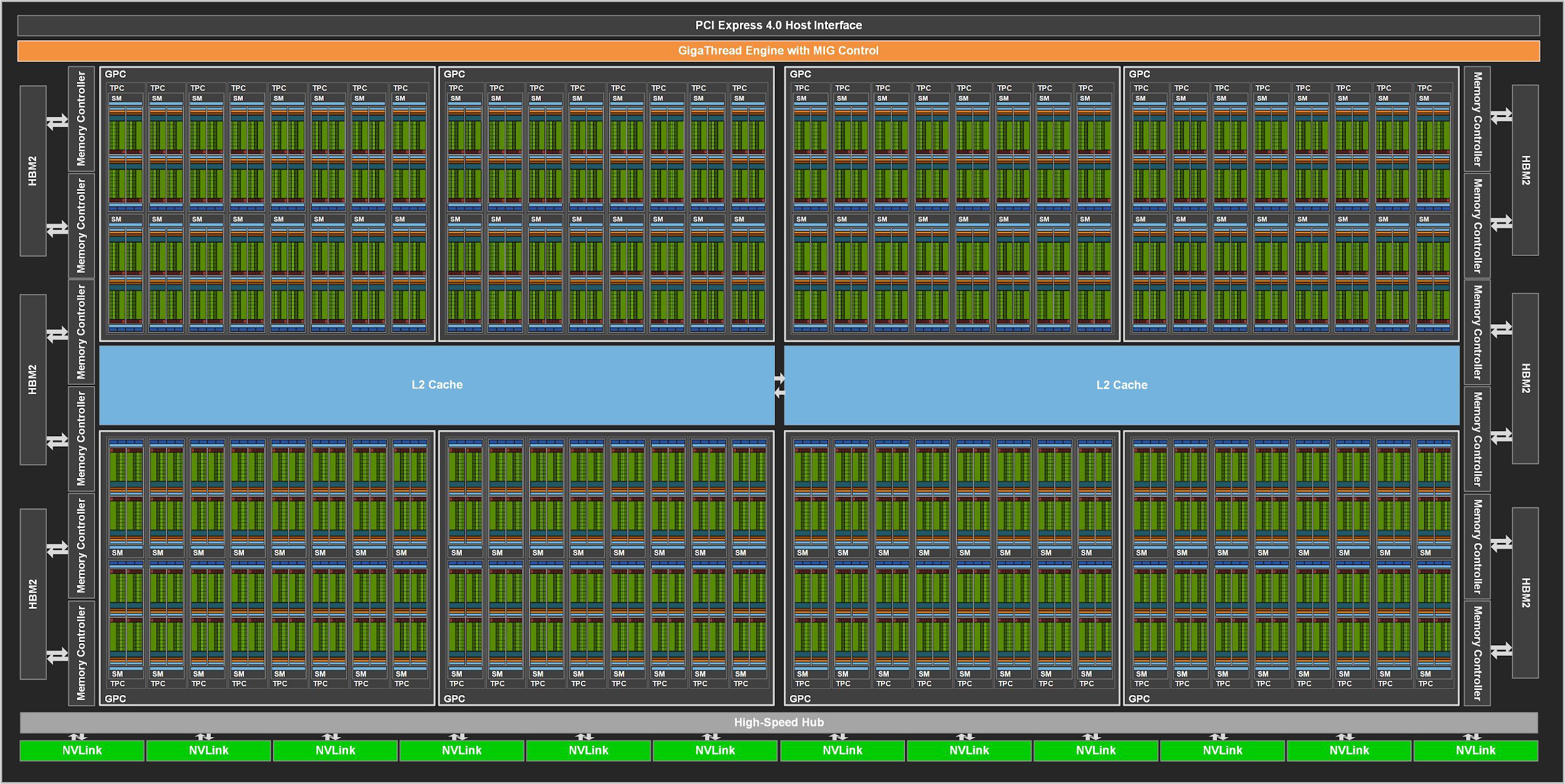
可以看到完整版的 GA100 擁有128組 SM,每組 SM 中擁有4個最新第三代 Tensor Cores,仍然是64個 CUDA Cores / SM 的結構。所以完整的 GA100 擁有8192個 CUDA 核心和512個第三代 Tensor Cores,因為它是純計算領域核心取向,所以沒有 RT Core,可以說是 Volta 架構的直屬繼承者,面積高達 826mm2,比 GV100 核心還要大,這還是用上了台積電的 7nm 製程。
A100 計算卡上面使用的 GA100 核心並不完整,被遮蔽了20組 SM,所以它的規模是108組 SM,6912個 CUDA 核心外加432個 Tensor Cores,可以提供約19.5 TFLOPS 單精度計算能力和9.7 TFLOPS 的雙精度計算能力。

Tensor Cores 在 Ampere 架構上面進化到了最新的第三代,NVIDIA 特別引入了全新的Tensor Float(TF32)數據格式,可以讓 Tensor Cores 在沒有改動代碼的情況下提高20倍的單精度性能,另外新的 Tensor Cores 加入了針對雙精度浮點的支援,可以在諸多場景中發揮出更大的作用。

GA100 上面還引入了新的多實例 GPU 功能,該功能支援將單 GPU 的計算資源切分成最多7塊,多任務也好,虛擬化也好,這個特性對資料數據中心是相當友善。

另外,用於 GPU 之間互聯的 NVLink 技術升級到了第三代,能夠提供最高600GB/s的數據傳輸速度,同時 GPU 的 PCIe 支援升級到了4.0版本,最高數據傳輸速度提升到了64GB/s。A100 計算卡使用了40GB的 HBM2 記憶體,能夠提供高達1.6TB/s的頻寬。
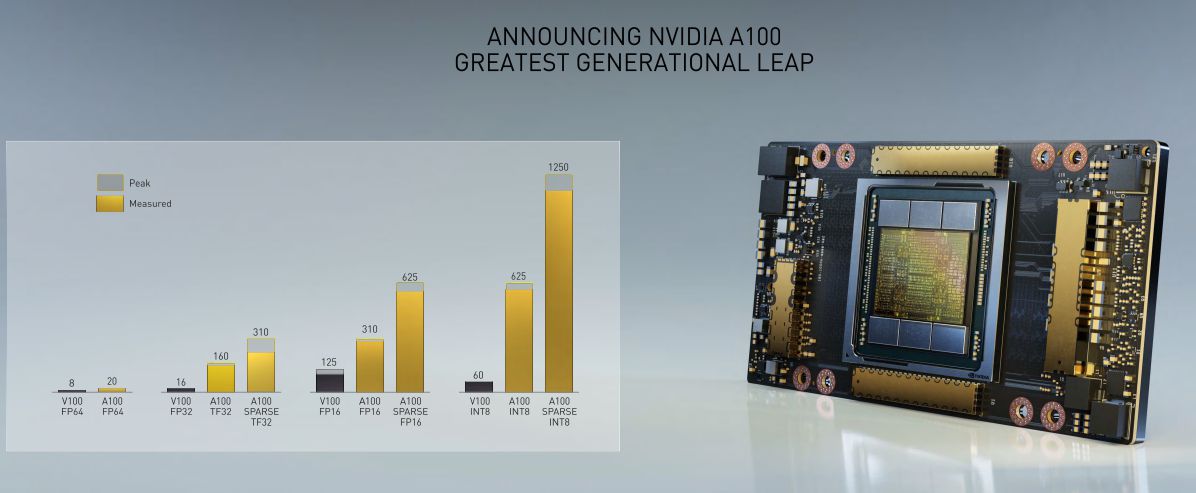
憑藉著架構和製程的升級,A100 計算卡的效能較上一代 V100 有相當的進步,各種官方數據中,它相比 V100 都是成幾倍的成長。
基於這張計算卡構建的 DGX A100 系統,則是高達 5PFLOPS 的計算能力(半精度),不過它的售價也貴,單節點的價格高達20萬美金。

來源
完整版的GA100核心架構圖如下:
可以看到完整版的 GA100 擁有128組 SM,每組 SM 中擁有4個最新第三代 Tensor Cores,仍然是64個 CUDA Cores / SM 的結構。所以完整的 GA100 擁有8192個 CUDA 核心和512個第三代 Tensor Cores,因為它是純計算領域核心取向,所以沒有 RT Core,可以說是 Volta 架構的直屬繼承者,面積高達 826mm2,比 GV100 核心還要大,這還是用上了台積電的 7nm 製程。
A100 計算卡上面使用的 GA100 核心並不完整,被遮蔽了20組 SM,所以它的規模是108組 SM,6912個 CUDA 核心外加432個 Tensor Cores,可以提供約19.5 TFLOPS 單精度計算能力和9.7 TFLOPS 的雙精度計算能力。
Tensor Cores 在 Ampere 架構上面進化到了最新的第三代,NVIDIA 特別引入了全新的Tensor Float(TF32)數據格式,可以讓 Tensor Cores 在沒有改動代碼的情況下提高20倍的單精度性能,另外新的 Tensor Cores 加入了針對雙精度浮點的支援,可以在諸多場景中發揮出更大的作用。
GA100 上面還引入了新的多實例 GPU 功能,該功能支援將單 GPU 的計算資源切分成最多7塊,多任務也好,虛擬化也好,這個特性對資料數據中心是相當友善。
另外,用於 GPU 之間互聯的 NVLink 技術升級到了第三代,能夠提供最高600GB/s的數據傳輸速度,同時 GPU 的 PCIe 支援升級到了4.0版本,最高數據傳輸速度提升到了64GB/s。A100 計算卡使用了40GB的 HBM2 記憶體,能夠提供高達1.6TB/s的頻寬。
憑藉著架構和製程的升級,A100 計算卡的效能較上一代 V100 有相當的進步,各種官方數據中,它相比 V100 都是成幾倍的成長。
基於這張計算卡構建的 DGX A100 系統,則是高達 5PFLOPS 的計算能力(半精度),不過它的售價也貴,單節點的價格高達20萬美金。
來源