
從2011年底首發 HD 7970 顯卡以來,AMD 使用 GCN 架構已經有5年多時間了,
同時針對圖形、計算雙重使命開發的 GCN 已經衍生出4代架構,時至今日依然是 AMD 顯卡的主流,
在異步運算等設計上很有前瞻性,在 DX12 / Vulkan 時代依然不落伍。
儘管如此,AMD 還是準備了新一代顯卡架構,昨晚正式公佈了 Vega 顯卡的架構設計,
GCN 架構將被 NCU 架構取代,不僅用上 HBM 2,還會使用新的 HBC 快取架構。

AMD 發布新一代 Vega 的架構細節如下:
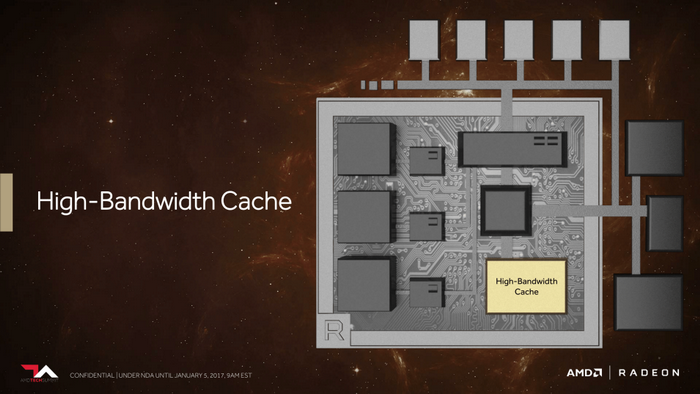
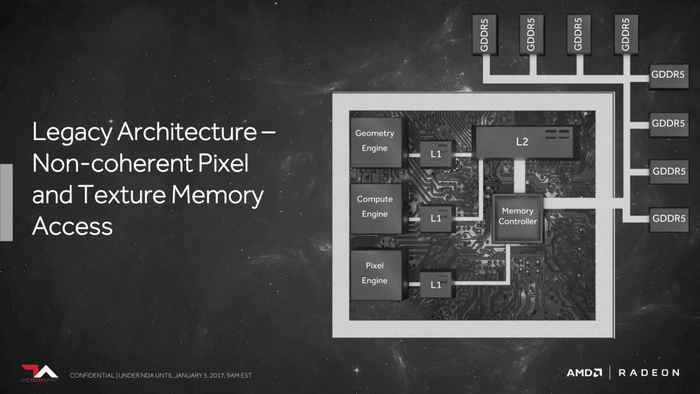
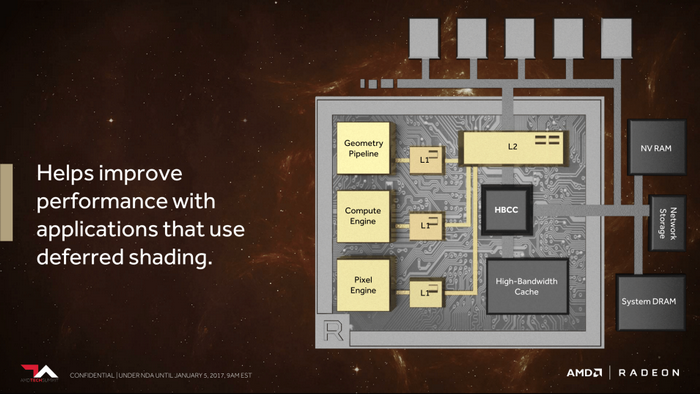
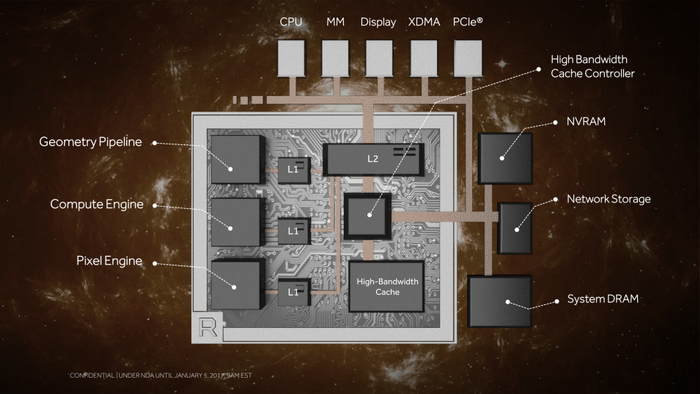
Vega顯卡新一代顯存架構
Vega顯卡新一代幾何渲染管線
Vega顯卡新一代NCU單元
Vega顯卡新一代像素引擎
不過 AMD 還未公佈 Vega 顯卡的具體規格,
包括串流處理器單元數量、核心頻率、記憶體頻率、效能水準、上市時間、售價等等。
Vega顯卡新一代記憶體架構
Vega 顯卡為人熟知的一個特點就是HBM 2,
在2015年的 Fiji 核心上 AMD 使用了第一代的 HBM 記憶體,
不過當時的 Fiji 架構並不是完全針對 HBM 開發,現在的 Vega 核心不同,
AMD 稱之為世界上最具並行性的 GPU 記憶體架構。

HBC 快取,HBM 2 不僅僅是記憶體,AMD 給的定義是高頻寬快取。
有關 HBM 2 記憶體的優勢,相比 HBM 1代1Gbps的速率,
HBM 2 的速率提升到2Gbps,這也是AMD宣稱2x頻寬/針腳的來源。

8倍密度,這是說 HBM 記憶體佔用的面積比GDDR5更低。

Techreport 網站所曝光的 Vega 核心照片。

上面的示意圖,可以看到 HBM 2 的配置方式跟 Fury 顯卡不同——
AMD之前是每個 GPU 核心堆棧4顆HBM,現在的 Vega 則是堆棧2顆,
這就解釋了 AMD 之前公佈的 Vega 顯卡在使用了速率翻倍的 HBM2 之後,
帶寬為何是512GB/s,只跟第一代 HBM 顯卡相同。
HBM 2 容量更大,三星、SK Hynix都可以做到單顆容量4GB,
Vega 顯卡只要2顆就能實現8GB容量,容量上比 Fury 顯卡擴大一倍,但堆棧數量少了一半,
導致等效位寬從4096bit減少到2048bit,所以總帶寬一降一升之後並沒有變化,還是512GB/s。
512GB/s 的顯卡帶寬在消費級產品依然是傲視群雄,比它高的是 Tesla P100 加速卡的720GB/s,
但後者是針對高效能伺服器市場,價格與消費級不能相比。
其次,AMD 這麼做顯然有助於降低成本,畢竟堆棧的 HBM 顆粒越少,製造難度也越低,成本也會更低。
HBCC 快取主控
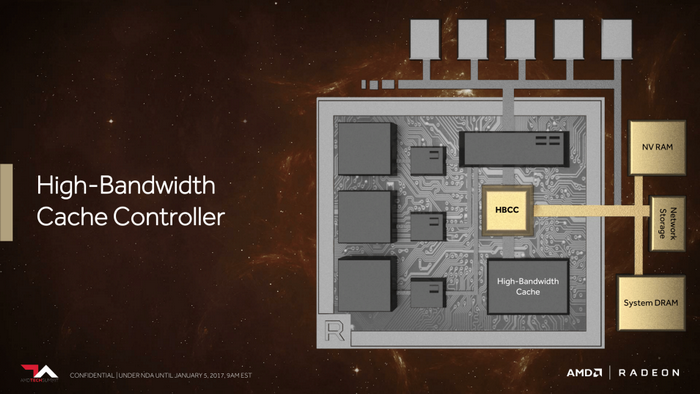
最高支援512TB虛擬尋址空間

自適應、細粒度數據遷移

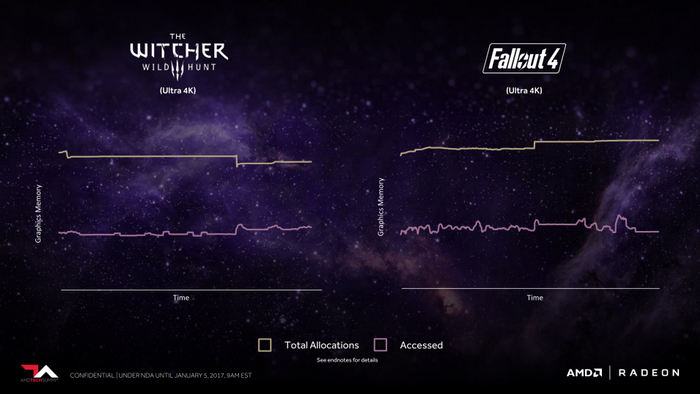
Fallout 4、Witcher 3 遊戲的實例,這兩款遊戲在分配的尋址空間要比實際佔用的高得多,
大約是實際使用的2倍,浪費嚴重。原因與DX11 API效率低有關,但也跟傳統遊戲的使用方式有關。
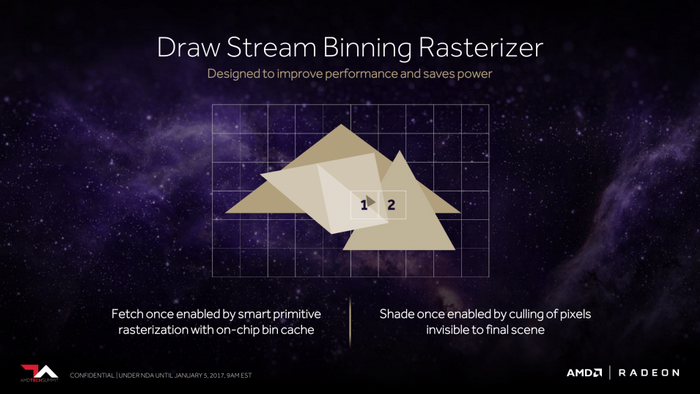
Vega顯卡新一代幾何渲染管線
Vega 顯卡第二個改進之處就是全新的可編程幾何渲染管線,
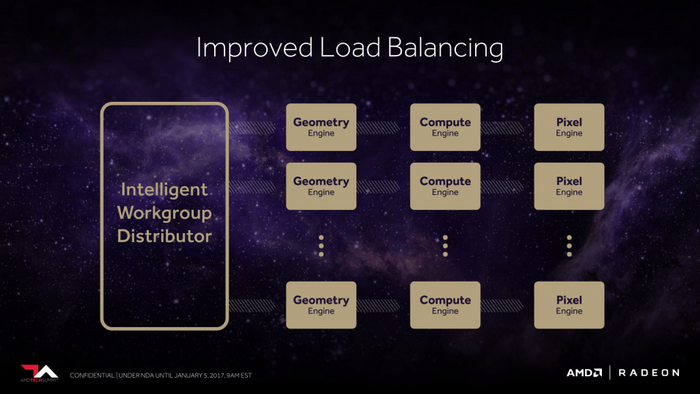
號稱每週期吞吐率提升一倍,並使用了新的原語渲染器,改善了載入均衡。


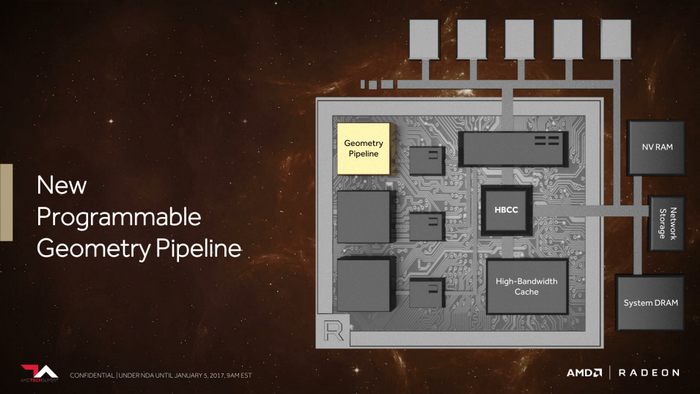
2倍的吞吐率

新的原語指令渲染器
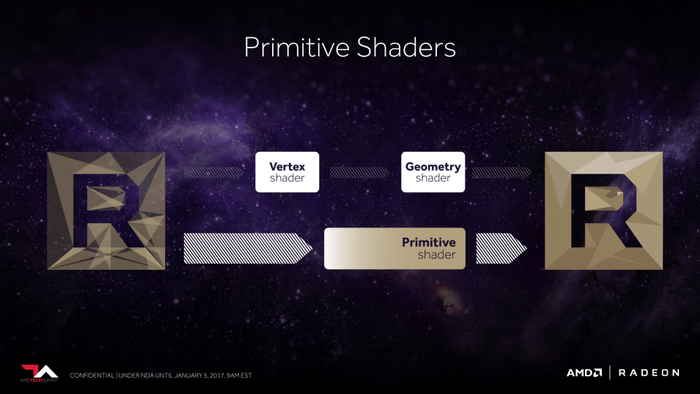
改善了載入均衡
Vega 顯卡新一代NCU單元
AMD 顯卡的 GCN 架構已經使用4代了,也該是更新的時候,
Vega 顯卡上 AMD 使用了 NCU(Next-Generation Compute Engine)架構,優化了IPC性能,提高了靈活性。
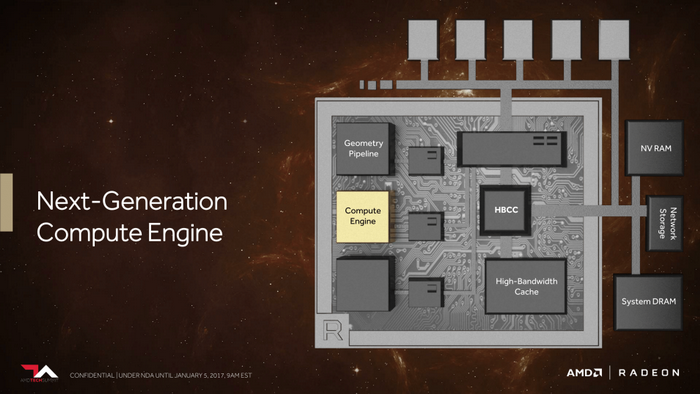
此前曝光的AMD NCU架構
AMD 在這次的PPT中並沒有詳細介紹 NUC 架構的特點,不過之前有消息提到了 NCU 的改進之處——
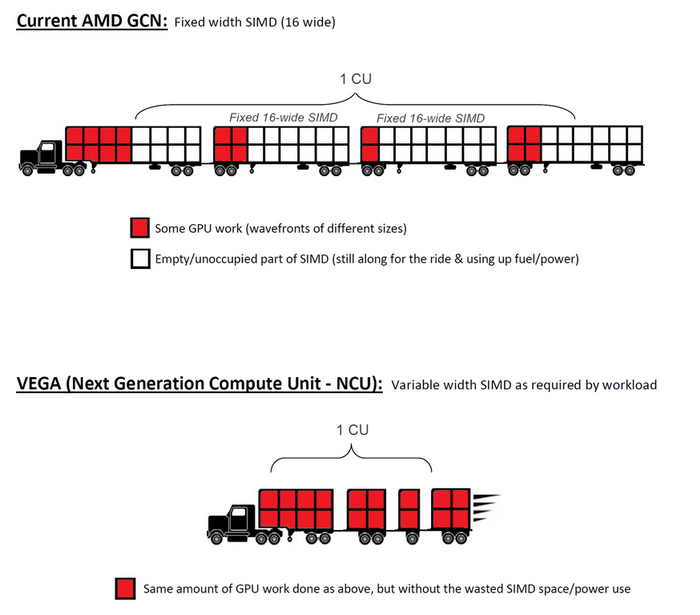
現有的 GCN單 元中每個CU計算單元是64個流處理器,實際上是由4組固定16-Wide的單元組成,
而 Vega 顯卡的 NCU 架構中每組CU單元更具靈活性,可以根據工作負載來動態調配。
除了常規的FP32單精度、FP64雙精度之外,NCU 還將支持8位、16位計算,性能還會翻倍甚至4倍,
這點其實也不是秘密了,因為之前公佈的 Radeon Instinct 專業卡中 MI25 就是基於 Vega 顯卡的,
其25TFLOPS的性能就是指FP16,FP32浮點性能是12.5TFLOPS。


NUC 為更高的時脈頻率優化

AMD 強調 NCU 是為更高的時脈頻率優化,顯然是在暗示 Vega 顯卡的頻率可以更高,
目前的 Polaris 顯卡雖然也是14nm,不過 GPU 核心頻率在1.5GHz以內,
這點比不上 NVIDIA 的 Pascal 顯卡,後者可以到1.8GHz以上,
現在 AMD 也強調 Vega 顯卡為更高的時脈頻率及 IPC 性能優化,核心頻率也能跑的更高。
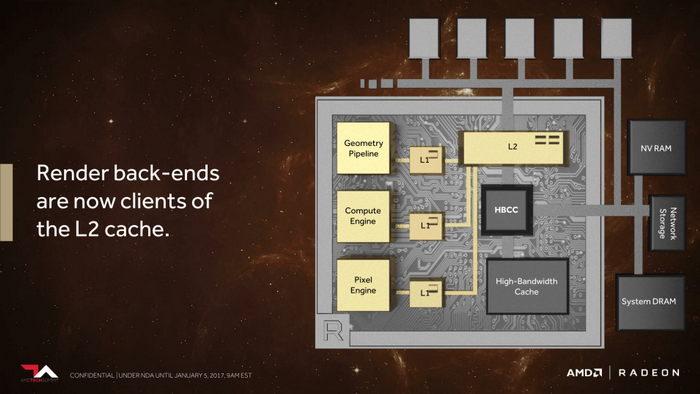
Vega顯卡新一代像素引擎

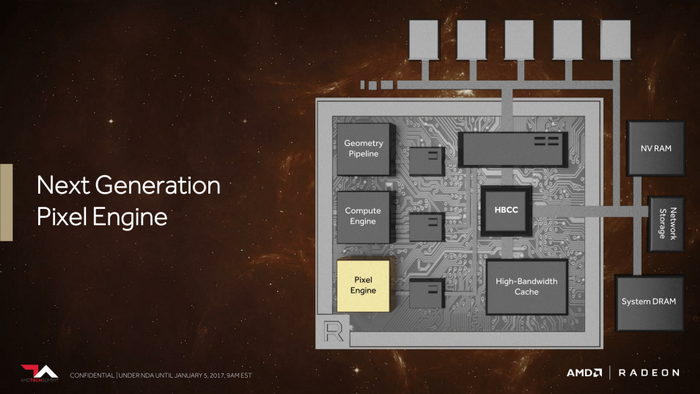
最後一部分改進就是新一代像素引擎了,目前傳統的架構中像素與紋理數據是非一致性的,
新的像素引擎現在是後端與L2快取相連,這將會提高使用延遲渲染技術的應用性能,
換句話說這個改進對VR渲染之類的應用很有價值。
來源:http://www.expreview.com/51769.html
同時針對圖形、計算雙重使命開發的 GCN 已經衍生出4代架構,時至今日依然是 AMD 顯卡的主流,
在異步運算等設計上很有前瞻性,在 DX12 / Vulkan 時代依然不落伍。
儘管如此,AMD 還是準備了新一代顯卡架構,昨晚正式公佈了 Vega 顯卡的架構設計,
GCN 架構將被 NCU 架構取代,不僅用上 HBM 2,還會使用新的 HBC 快取架構。
AMD 發布新一代 Vega 的架構細節如下:
Vega顯卡新一代顯存架構
Vega顯卡新一代幾何渲染管線
Vega顯卡新一代NCU單元
Vega顯卡新一代像素引擎
不過 AMD 還未公佈 Vega 顯卡的具體規格,
包括串流處理器單元數量、核心頻率、記憶體頻率、效能水準、上市時間、售價等等。
Vega顯卡新一代記憶體架構
Vega 顯卡為人熟知的一個特點就是HBM 2,
在2015年的 Fiji 核心上 AMD 使用了第一代的 HBM 記憶體,
不過當時的 Fiji 架構並不是完全針對 HBM 開發,現在的 Vega 核心不同,
AMD 稱之為世界上最具並行性的 GPU 記憶體架構。
HBC 快取,HBM 2 不僅僅是記憶體,AMD 給的定義是高頻寬快取。
有關 HBM 2 記憶體的優勢,相比 HBM 1代1Gbps的速率,
HBM 2 的速率提升到2Gbps,這也是AMD宣稱2x頻寬/針腳的來源。
8倍密度,這是說 HBM 記憶體佔用的面積比GDDR5更低。
Techreport 網站所曝光的 Vega 核心照片。
上面的示意圖,可以看到 HBM 2 的配置方式跟 Fury 顯卡不同——
AMD之前是每個 GPU 核心堆棧4顆HBM,現在的 Vega 則是堆棧2顆,
這就解釋了 AMD 之前公佈的 Vega 顯卡在使用了速率翻倍的 HBM2 之後,
帶寬為何是512GB/s,只跟第一代 HBM 顯卡相同。
HBM 2 容量更大,三星、SK Hynix都可以做到單顆容量4GB,
Vega 顯卡只要2顆就能實現8GB容量,容量上比 Fury 顯卡擴大一倍,但堆棧數量少了一半,
導致等效位寬從4096bit減少到2048bit,所以總帶寬一降一升之後並沒有變化,還是512GB/s。
512GB/s 的顯卡帶寬在消費級產品依然是傲視群雄,比它高的是 Tesla P100 加速卡的720GB/s,
但後者是針對高效能伺服器市場,價格與消費級不能相比。
其次,AMD 這麼做顯然有助於降低成本,畢竟堆棧的 HBM 顆粒越少,製造難度也越低,成本也會更低。
HBCC 快取主控
最高支援512TB虛擬尋址空間
自適應、細粒度數據遷移
Fallout 4、Witcher 3 遊戲的實例,這兩款遊戲在分配的尋址空間要比實際佔用的高得多,
大約是實際使用的2倍,浪費嚴重。原因與DX11 API效率低有關,但也跟傳統遊戲的使用方式有關。
Vega顯卡新一代幾何渲染管線
Vega 顯卡第二個改進之處就是全新的可編程幾何渲染管線,
號稱每週期吞吐率提升一倍,並使用了新的原語渲染器,改善了載入均衡。
2倍的吞吐率
新的原語指令渲染器
改善了載入均衡
Vega 顯卡新一代NCU單元
AMD 顯卡的 GCN 架構已經使用4代了,也該是更新的時候,
Vega 顯卡上 AMD 使用了 NCU(Next-Generation Compute Engine)架構,優化了IPC性能,提高了靈活性。
此前曝光的AMD NCU架構
AMD 在這次的PPT中並沒有詳細介紹 NUC 架構的特點,不過之前有消息提到了 NCU 的改進之處——
現有的 GCN單 元中每個CU計算單元是64個流處理器,實際上是由4組固定16-Wide的單元組成,
而 Vega 顯卡的 NCU 架構中每組CU單元更具靈活性,可以根據工作負載來動態調配。
除了常規的FP32單精度、FP64雙精度之外,NCU 還將支持8位、16位計算,性能還會翻倍甚至4倍,
這點其實也不是秘密了,因為之前公佈的 Radeon Instinct 專業卡中 MI25 就是基於 Vega 顯卡的,
其25TFLOPS的性能就是指FP16,FP32浮點性能是12.5TFLOPS。
NUC 為更高的時脈頻率優化
AMD 強調 NCU 是為更高的時脈頻率優化,顯然是在暗示 Vega 顯卡的頻率可以更高,
目前的 Polaris 顯卡雖然也是14nm,不過 GPU 核心頻率在1.5GHz以內,
這點比不上 NVIDIA 的 Pascal 顯卡,後者可以到1.8GHz以上,
現在 AMD 也強調 Vega 顯卡為更高的時脈頻率及 IPC 性能優化,核心頻率也能跑的更高。
Vega顯卡新一代像素引擎
最後一部分改進就是新一代像素引擎了,目前傳統的架構中像素與紋理數據是非一致性的,
新的像素引擎現在是後端與L2快取相連,這將會提高使用延遲渲染技術的應用性能,
換句話說這個改進對VR渲染之類的應用很有價值。
來源:http://www.expreview.com/51769.html